
이번 미니 프로젝트는 SPOTIFY API 데이터로 음악 추천 웹을 개발하는 프로젝트입니다! 프로젝트 기간으로 주어진 5일 간은 웹에 집중하고, 이후엔 데이터 파이프라인을 체계적으로 구축해보려고 합니다. 지금은 프로젝트 기간 2일이 지난 상태고, 앞서 진행했던 SPOTIFY API 사용, 데이터 베이스 설계, AWS RDS 연동, 그리고 DJANGO의 간단한 검색 기능 구현 과정을 담은 포스팅입니다!
SPOTIFY API
먼저 SPOTFIY API를 활용해서, 데이터를 받아오는 과정이 있었습니다. SPOTIFY DEVELOPERS에서 가입을 한 후에 KEY를 통해 데이터를 받을 수 있습니다. 다만, 토큰이 일정 시간이 지나면 초기화되고, 너무 많은 요청이 있을 때는 몇 분정도 기다려야하는 단점이 있습니다. 지금은 단순히 일회성으로 받아오는 수준이여서, 아직까지 api 에러에 관한 대처 코드는 없지만, 이후 업데이트할 예정입니다. 파이썬에서 가장 단순하게 데이터를 받아올 수 있는 코드는 다음과 같습니다.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import pandas as pd
client_id = '클라이언트 ID'
client_secret = '클라이언트 SECRET'
client_credentials_manager = SpotifyClientCredentials(client_id= client_id, client_secret= client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
# JSON 형식의 API를 반복을 통해 리스트에 담고, 각 리스트에 담긴 데이터를 PANDAS로 데이터프레임으로 만드는 과정입니다.
artist_name =[]
track_name = []
track_popularity =[]
artist_id =[]
track_id =[]
track_images = []
for i in range(0,1000,50):
track_results = sp.search(q='year:2021', type='track', limit=50, offset=i)
for i, t in enumerate(track_results['tracks']['items']):
artist_name.append(t['artists'][0]['name'])
artist_id.append(t['artists'][0]['id'])
track_name.append(t['name'])
track_id.append(t['id'])
track_popularity.append(t['popularity'])
track_images.append(t['album']['images'][0]['url'])
track_df = pd.DataFrame({'track_name' : track_name, 'track_id' : track_id, 'track_popularity' : track_popularity, 'artist_name' : artist_name, 'artist_id' : artist_id, 'track_image_link': track_images})만에 하나 append시에, None 값이 발생할 수 있는데 각 append마다 try except를 통해서 오류제어를 해주는 편이 더 좋은 코드 일 수 있습니다. 또한 토큰 초기화 오류, 지연 발생 시 time sleep을 넣어주는 등, 해당 Extract 과정을 조금 더 원활하게 돌아가기 위한 추가 방식이 필요합니다. 지금은 일회성으로 1000개의 데이터만 뽑아서 웹에 적용 중이라, 일단은 이렇게 진행했습니다. 이외에도 다양한 api가 있는데 위에 보이는 sp 변수를 활용하면, 다양한 데이터를 가져올 수 있습니다. SPOTIFY API의 참조 문서는 첨부해두겠습니다!
https://developer.spotify.com/documentation/web-api
Web API | Spotify for Developers
Spotify Web API enables the creation of applications that can interact with Spotify's streaming service, such as retrieving content metadata, getting recommendations, creating and managing playlists, or controlling playback. This is where the magic begins!
developer.spotify.com
AWS RDS
AWS RDS는 쉽게 사용하고, 쉽게 확장이 가능하다는 장점이 있습니다. 이번 프로젝트에서는 AWS의 RDS를 웹 운영 DB로 활용할 예정입니다. 프리티어의 경우에는 20GB까지 사용이 가능하고, 한 달간의 사용량이 750시간을 넘지 않고, 12개월간 무료로 이용 가능합니다. 저희는 MYSQL로 데이터베이스를 선정했습니다. AWS의 RDS 프리티어 사용법은 간단하게 유튜브에 업로드 해신 분이 있어, 링크 첨부합니다.
https://www.youtube.com/watch?v=wdaMD6yQVh4
저희가 설계한 데이터는 아직까지는 tracks와 artists로 두 테이블만을 가지고, 일단은 간단히 웹을 구현할 생각입니다. 지금의 데이터베이스 설계는 이렇습니다.
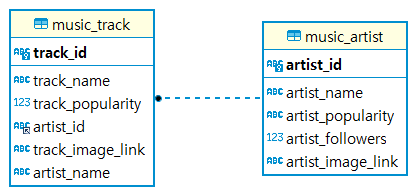
지금은 굉장히 초라하지만, track 테이블을 설계하는데에 있어서 한가지 고민이 있었습니다. 정규화에 대한 강박? 같은 점이였는데, music_track 테이블에 있는 artist_name에서 부분 함수 종속을 제거하기 위해서 원래는 artist_name을 제외하고 설계했습니다. 하지만 웹을 구현하는데에 있어서 music_track 테이블에서만 데이터를 가져오는 게 데이터가 커질 때를 대비해서 조금 더 유리할 거라고 생각하고, 일단 반정규화라고 생각하고 넣어둔 상황입니다.
다만 앞으로 음악을 검색하는 것에 있어서 elastic search를 사용할 수도 있는 상황이여서, 조금 더 팀원과 협의 후에 다시 설계할 예정입니다.
SQL ALCHEMY
지금은 SPOTIFY API에서 받아온 데이터를, SQL ALCHEMY를 통해 DB에 일회성으로 집어넣고 있는 상황입니다. 추후에는 특정 파이프라인을 거쳐서, 에어플로우를 통해 계속해서 데이터를 업데이트해볼 생각입니다. ALCHEMY로 데이터를 적재하는 베이스 코드는 다음과 같습니다.
from sqlalchemy import create_engine
def connect_mysql(user_id, user_password, ip, port_number, database_name):
'''mysql 연결하는 함수, {user_id : db 유저 아이디, user_password : db 유저 패스워드, ip : 주소, port_number : mysql 포트번호, database_name : 데이터베이스 이름}'''
engine = create_engine(f"mysql+pymysql://{user_id}:"+f"{user_password}"+f"@{ip}:{port_number}/{database_name}?charset=utf8")
conn = engine.connect()
return conn, engine
이 코드는 create_engine 과정에서 자꾸 쓰는 방식을 까먹어서 만들어둔 함수인데, 공유드립니다!
검색 기능 만들기
빅데이터 환경에서 검색 기능을 만드는 것을 중점으로, 추후에는 자동완성 기능까지 넣을 예정입니다. 하지만 이번 미니프로젝트 기간 동안에는 elastic search를 쓰지 않고, RDB로만 검색 기능을 활용할 생각입니다. DJANGO에서 제공하는 FILTER를 활용해서 검색 중입니다. 기능은 구현은 되고 있으나, aba를 타이핑 했을 때, aba가 포함된 것들을 모두 검색해서 문제가 있는 것 같습니다. 이 외엔 작동은 잘되고 있으나, 나중에 데이터가 커졌을 때 RDB의 한계점이 분명히 드러날 것이라고 생각합니다. 이 부분에서 팀원과 계속해서 고민 중입니다. 일단은 간단하게 views와 html 장고 템플릿 언어를 활용해서 사용하고 있는 검색 및 검색 결과 반환 로직입니다.
def search_results(request):
query = request.GET.get('q')
artists = Artist.objects.filter(artist_name__icontains=query)
tracks = Track.objects.filter(track_name__icontains=query)
results = list(artists) + list(tracks)
return render(request, 'music/search_results.html', {'results': results, 'query': query})검색어로 받아온 문장을 artist 테이블의 artist name, 그리고 tracks 테이블의 track_name의 포함관계를 조회하는 orm을 통해 조회합니다. 이후 result로 나온 값을 list로 합칩니다.
<div class="subtitle">
<h2>아티스트</h2>
{% if results %}
{% for result in results %}
{% if result|class_name == 'Artist' %}
<ul>
<li>
<img src="{{ result.artist_image_link }}" alt="{{ result.artist_name }}">
<a href="{% url 'music:artist_page' result.artist_id %}">{{ result.artist_name }}</a>
</li>
</ul>
{% endif %}
{% endfor %}
{% else %}
<p>찾으시는 "{{ query }}"에 대한 검색 결과는 없습니다😭</p>
{% endif %}합친 list는 class_name(사용자 정의함수 사용)을 통해서 Artist, Track으로 분리되어 각각 표시합니다. 이렇게 구현한 이유는, 같은 검색 값에 대해서 아티스트와 트랙에 대한 모든 검색을 진행했으면 했습니다. 다만 이런 방법들이 조금 더 정교하고, 더 나은 성능으로 구현되려고 한다면 확실히 elastic search나 다른 검색을 위한 데이터베이스가 반드시 필요하겠다는 생각이 들었습니다.
다음은 구현 상황입니다.
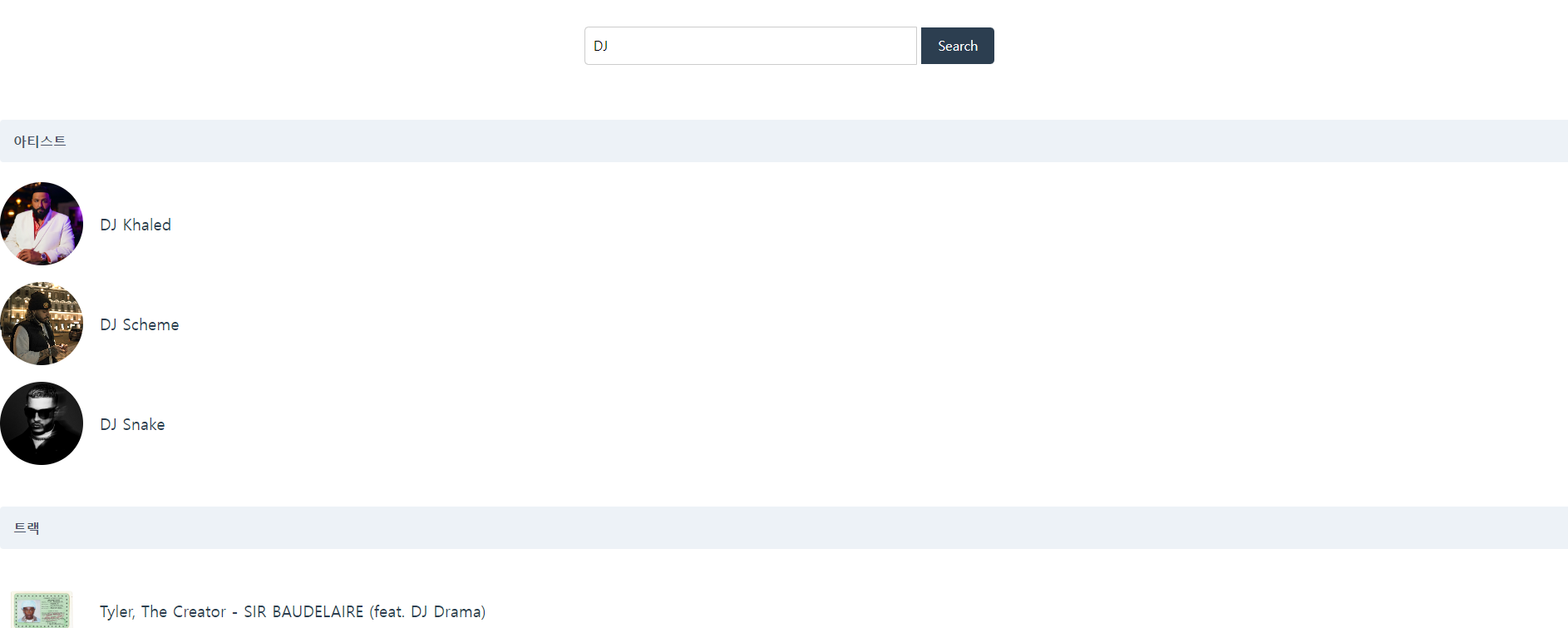
검색 된 아티스트나, 트랙을 클릭해서 들어가면 해당 아티스트의 음악이 나오는 창이 나옵니다.
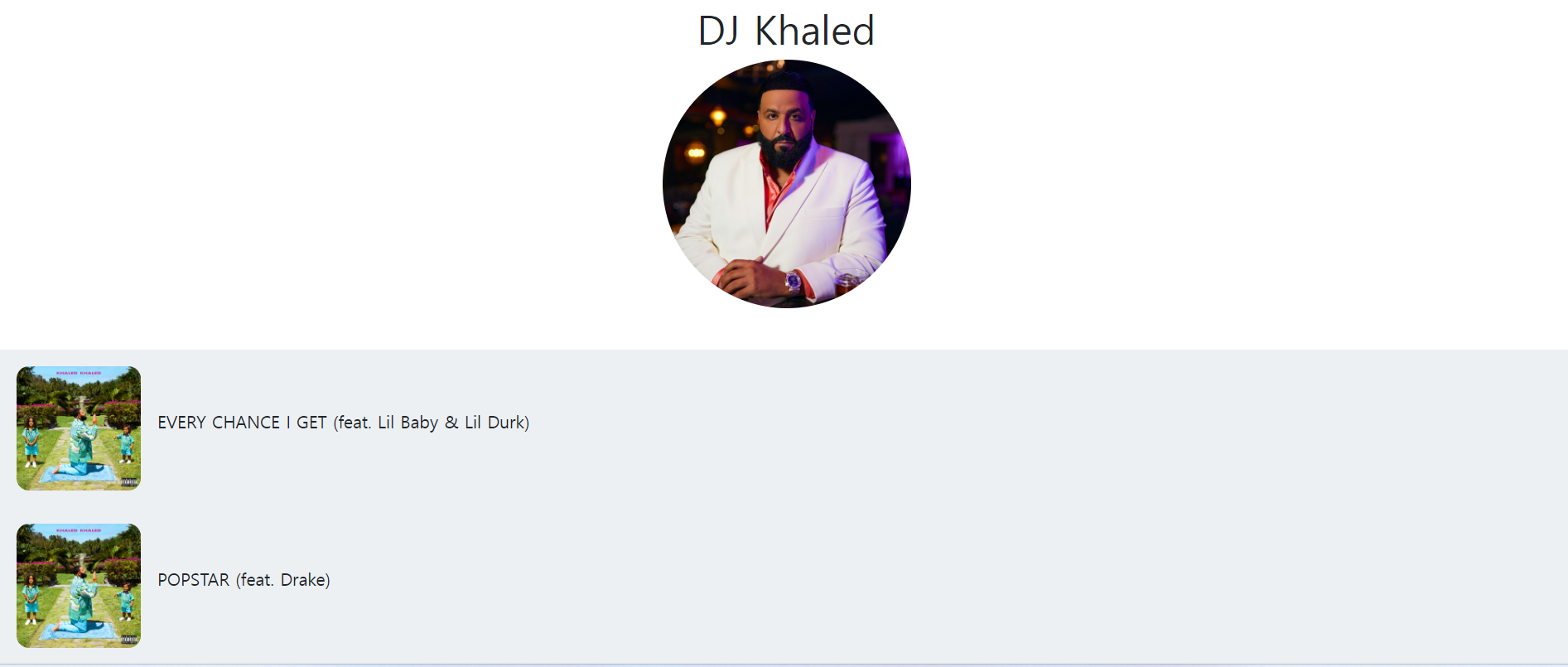
아직은 프론트도 구현이 되지 않았고, 데이터도 1000개의 음악 정도만 들어간 상태라 빈약합니다.., 일단은 지금 뼈대를 만들어두고 있는 상황이고, 데이터가 들어가면 조금 더 많은 데이터를 보여줘야해서, 아직은 구현되지 않은 페이징 기능도 붙을 예정입니다.
일단 이 외에도 로그인, 회원가입은 다른 팀원인 병창님께서 진행하셨고, 오늘 나온 뼈대 웹을 토대로 좋아요 기능, 음악 재생 기능, 사용자 좋아요 기반 음악 추천 등이 덧붙을 예정입니다. 음악 추천 알고리즘은 간단히 내일 구현해볼 예정이고, 데이터엔지니어링의 파트의 경우엔 지속적으로 업데이트해서 올리겠습니다. 완성이 되면 모든 코드는 git을 통해 공유 드리겠습니다. 감사합니다:)
'웹 애플리케이션 > Django(장고)' 카테고리의 다른 글
| [Django] 로그인, 회원가입 기능 구현 (1) | 2023.04.20 |
|---|---|
| [Django] 페이징 기능 (0) | 2023.04.19 |
| [Django] 템플릿 include (0) | 2023.04.19 |
| [Django] 화면 꾸미기 (1) | 2023.04.19 |
| [Django] 관리자 계정 및 페이지, 동적 URL, 별칭 (0) | 2023.04.13 |
이번 미니 프로젝트는 SPOTIFY API 데이터로 음악 추천 웹을 개발하는 프로젝트입니다! 프로젝트 기간으로 주어진 5일 간은 웹에 집중하고, 이후엔 데이터 파이프라인을 체계적으로 구축해보려고 합니다. 지금은 프로젝트 기간 2일이 지난 상태고, 앞서 진행했던 SPOTIFY API 사용, 데이터 베이스 설계, AWS RDS 연동, 그리고 DJANGO의 간단한 검색 기능 구현 과정을 담은 포스팅입니다!
SPOTIFY API
먼저 SPOTFIY API를 활용해서, 데이터를 받아오는 과정이 있었습니다. SPOTIFY DEVELOPERS에서 가입을 한 후에 KEY를 통해 데이터를 받을 수 있습니다. 다만, 토큰이 일정 시간이 지나면 초기화되고, 너무 많은 요청이 있을 때는 몇 분정도 기다려야하는 단점이 있습니다. 지금은 단순히 일회성으로 받아오는 수준이여서, 아직까지 api 에러에 관한 대처 코드는 없지만, 이후 업데이트할 예정입니다. 파이썬에서 가장 단순하게 데이터를 받아올 수 있는 코드는 다음과 같습니다.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import pandas as pd
client_id = '클라이언트 ID'
client_secret = '클라이언트 SECRET'
client_credentials_manager = SpotifyClientCredentials(client_id= client_id, client_secret= client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
# JSON 형식의 API를 반복을 통해 리스트에 담고, 각 리스트에 담긴 데이터를 PANDAS로 데이터프레임으로 만드는 과정입니다.
artist_name =[]
track_name = []
track_popularity =[]
artist_id =[]
track_id =[]
track_images = []
for i in range(0,1000,50):
track_results = sp.search(q='year:2021', type='track', limit=50, offset=i)
for i, t in enumerate(track_results['tracks']['items']):
artist_name.append(t['artists'][0]['name'])
artist_id.append(t['artists'][0]['id'])
track_name.append(t['name'])
track_id.append(t['id'])
track_popularity.append(t['popularity'])
track_images.append(t['album']['images'][0]['url'])
track_df = pd.DataFrame({'track_name' : track_name, 'track_id' : track_id, 'track_popularity' : track_popularity, 'artist_name' : artist_name, 'artist_id' : artist_id, 'track_image_link': track_images})만에 하나 append시에, None 값이 발생할 수 있는데 각 append마다 try except를 통해서 오류제어를 해주는 편이 더 좋은 코드 일 수 있습니다. 또한 토큰 초기화 오류, 지연 발생 시 time sleep을 넣어주는 등, 해당 Extract 과정을 조금 더 원활하게 돌아가기 위한 추가 방식이 필요합니다. 지금은 일회성으로 1000개의 데이터만 뽑아서 웹에 적용 중이라, 일단은 이렇게 진행했습니다. 이외에도 다양한 api가 있는데 위에 보이는 sp 변수를 활용하면, 다양한 데이터를 가져올 수 있습니다. SPOTIFY API의 참조 문서는 첨부해두겠습니다!
https://developer.spotify.com/documentation/web-api
Web API | Spotify for Developers
Spotify Web API enables the creation of applications that can interact with Spotify's streaming service, such as retrieving content metadata, getting recommendations, creating and managing playlists, or controlling playback. This is where the magic begins!
developer.spotify.com
AWS RDS
AWS RDS는 쉽게 사용하고, 쉽게 확장이 가능하다는 장점이 있습니다. 이번 프로젝트에서는 AWS의 RDS를 웹 운영 DB로 활용할 예정입니다. 프리티어의 경우에는 20GB까지 사용이 가능하고, 한 달간의 사용량이 750시간을 넘지 않고, 12개월간 무료로 이용 가능합니다. 저희는 MYSQL로 데이터베이스를 선정했습니다. AWS의 RDS 프리티어 사용법은 간단하게 유튜브에 업로드 해신 분이 있어, 링크 첨부합니다.
https://www.youtube.com/watch?v=wdaMD6yQVh4
저희가 설계한 데이터는 아직까지는 tracks와 artists로 두 테이블만을 가지고, 일단은 간단히 웹을 구현할 생각입니다. 지금의 데이터베이스 설계는 이렇습니다.
지금은 굉장히 초라하지만, track 테이블을 설계하는데에 있어서 한가지 고민이 있었습니다. 정규화에 대한 강박? 같은 점이였는데, music_track 테이블에 있는 artist_name에서 부분 함수 종속을 제거하기 위해서 원래는 artist_name을 제외하고 설계했습니다. 하지만 웹을 구현하는데에 있어서 music_track 테이블에서만 데이터를 가져오는 게 데이터가 커질 때를 대비해서 조금 더 유리할 거라고 생각하고, 일단 반정규화라고 생각하고 넣어둔 상황입니다.
다만 앞으로 음악을 검색하는 것에 있어서 elastic search를 사용할 수도 있는 상황이여서, 조금 더 팀원과 협의 후에 다시 설계할 예정입니다.
SQL ALCHEMY
지금은 SPOTIFY API에서 받아온 데이터를, SQL ALCHEMY를 통해 DB에 일회성으로 집어넣고 있는 상황입니다. 추후에는 특정 파이프라인을 거쳐서, 에어플로우를 통해 계속해서 데이터를 업데이트해볼 생각입니다. ALCHEMY로 데이터를 적재하는 베이스 코드는 다음과 같습니다.
from sqlalchemy import create_engine
def connect_mysql(user_id, user_password, ip, port_number, database_name):
'''mysql 연결하는 함수, {user_id : db 유저 아이디, user_password : db 유저 패스워드, ip : 주소, port_number : mysql 포트번호, database_name : 데이터베이스 이름}'''
engine = create_engine(f"mysql+pymysql://{user_id}:"+f"{user_password}"+f"@{ip}:{port_number}/{database_name}?charset=utf8")
conn = engine.connect()
return conn, engine
이 코드는 create_engine 과정에서 자꾸 쓰는 방식을 까먹어서 만들어둔 함수인데, 공유드립니다!
검색 기능 만들기
빅데이터 환경에서 검색 기능을 만드는 것을 중점으로, 추후에는 자동완성 기능까지 넣을 예정입니다. 하지만 이번 미니프로젝트 기간 동안에는 elastic search를 쓰지 않고, RDB로만 검색 기능을 활용할 생각입니다. DJANGO에서 제공하는 FILTER를 활용해서 검색 중입니다. 기능은 구현은 되고 있으나, aba를 타이핑 했을 때, aba가 포함된 것들을 모두 검색해서 문제가 있는 것 같습니다. 이 외엔 작동은 잘되고 있으나, 나중에 데이터가 커졌을 때 RDB의 한계점이 분명히 드러날 것이라고 생각합니다. 이 부분에서 팀원과 계속해서 고민 중입니다. 일단은 간단하게 views와 html 장고 템플릿 언어를 활용해서 사용하고 있는 검색 및 검색 결과 반환 로직입니다.
def search_results(request):
query = request.GET.get('q')
artists = Artist.objects.filter(artist_name__icontains=query)
tracks = Track.objects.filter(track_name__icontains=query)
results = list(artists) + list(tracks)
return render(request, 'music/search_results.html', {'results': results, 'query': query})검색어로 받아온 문장을 artist 테이블의 artist name, 그리고 tracks 테이블의 track_name의 포함관계를 조회하는 orm을 통해 조회합니다. 이후 result로 나온 값을 list로 합칩니다.
<div class="subtitle">
<h2>아티스트</h2>
{% if results %}
{% for result in results %}
{% if result|class_name == 'Artist' %}
<ul>
<li>
<img src="{{ result.artist_image_link }}" alt="{{ result.artist_name }}">
<a href="{% url 'music:artist_page' result.artist_id %}">{{ result.artist_name }}</a>
</li>
</ul>
{% endif %}
{% endfor %}
{% else %}
<p>찾으시는 "{{ query }}"에 대한 검색 결과는 없습니다😭</p>
{% endif %}합친 list는 class_name(사용자 정의함수 사용)을 통해서 Artist, Track으로 분리되어 각각 표시합니다. 이렇게 구현한 이유는, 같은 검색 값에 대해서 아티스트와 트랙에 대한 모든 검색을 진행했으면 했습니다. 다만 이런 방법들이 조금 더 정교하고, 더 나은 성능으로 구현되려고 한다면 확실히 elastic search나 다른 검색을 위한 데이터베이스가 반드시 필요하겠다는 생각이 들었습니다.
다음은 구현 상황입니다.
검색 된 아티스트나, 트랙을 클릭해서 들어가면 해당 아티스트의 음악이 나오는 창이 나옵니다.
아직은 프론트도 구현이 되지 않았고, 데이터도 1000개의 음악 정도만 들어간 상태라 빈약합니다.., 일단은 지금 뼈대를 만들어두고 있는 상황이고, 데이터가 들어가면 조금 더 많은 데이터를 보여줘야해서, 아직은 구현되지 않은 페이징 기능도 붙을 예정입니다.
일단 이 외에도 로그인, 회원가입은 다른 팀원인 병창님께서 진행하셨고, 오늘 나온 뼈대 웹을 토대로 좋아요 기능, 음악 재생 기능, 사용자 좋아요 기반 음악 추천 등이 덧붙을 예정입니다. 음악 추천 알고리즘은 간단히 내일 구현해볼 예정이고, 데이터엔지니어링의 파트의 경우엔 지속적으로 업데이트해서 올리겠습니다. 완성이 되면 모든 코드는 git을 통해 공유 드리겠습니다. 감사합니다:)
'웹 애플리케이션 > Django(장고)' 카테고리의 다른 글
| [Django] 로그인, 회원가입 기능 구현 (1) | 2023.04.20 |
|---|---|
| [Django] 페이징 기능 (0) | 2023.04.19 |
| [Django] 템플릿 include (0) | 2023.04.19 |
| [Django] 화면 꾸미기 (1) | 2023.04.19 |
| [Django] 관리자 계정 및 페이지, 동적 URL, 별칭 (0) | 2023.04.13 |