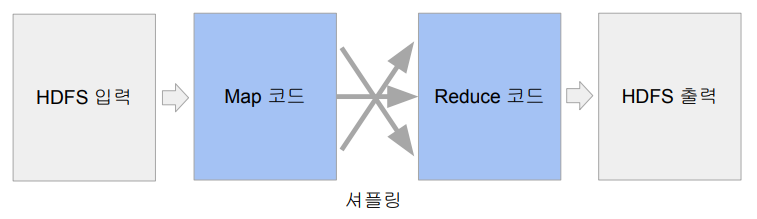
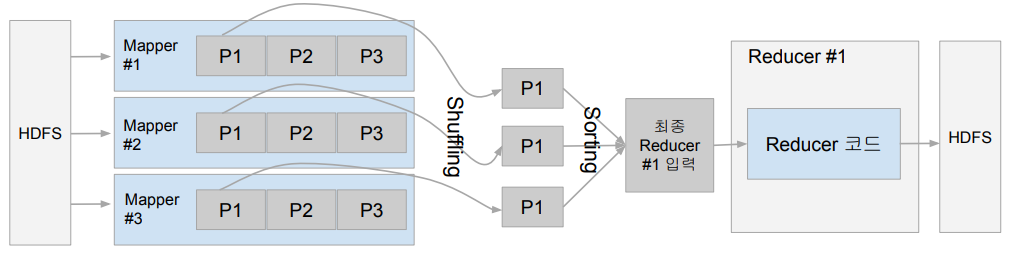
map이 돌아가는 서버와 reduce 돌아가는 서버가 다르기 때문에, 네트워크를 통한 데이터 전송
이 셔플링 과정이 길어질 경우, 데이터 처리 과정이 길어짐
맵 리듀스 프로그래밍의 핵심 : 맵과 리듀스
Map : (k, v) -> [(k',v')]
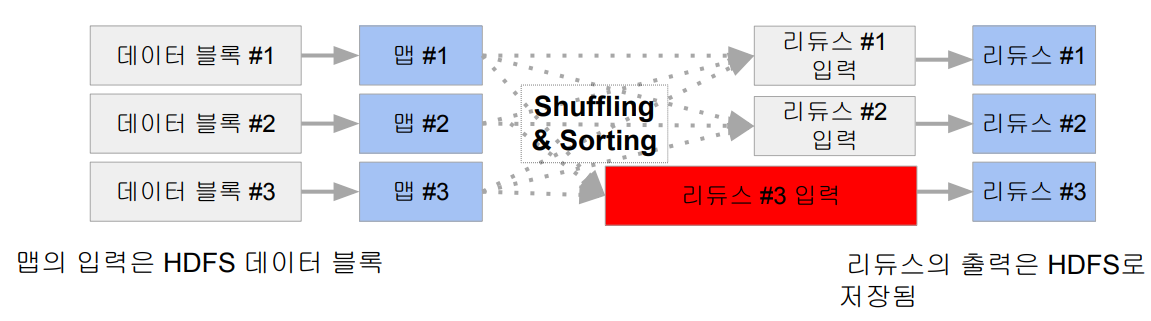
입력은 시스템에 의해 주어지며 입력으로 지정된 HDFS 파일에서 넘어옴
키, 밸류 페어를 새로운 키, 밸류 페어 리스트로 변환(transformation)
출력 : 입력과 동일한 키, 밸류 페어를 그대로 출력해도 되고, 출력이 없어도 됨
Reduce(k', [v1', v2', v3', v4',...]) -> (k", v")
입력은 시스템에 의해 주어짐
맵의 출력 중 같은 키를 갖는 키/밸류 페어를 시스템이 묶어서 입력으로 넣어줌
키와 밸류 리스트를 새로운 키, 밸류 페어로 변환
SQL의 GROUP BY와 흡사
출력이 HDFS에 저장됨
MapReduce 프로그램 동작 예시
Word Count
보통 이럴 때는 key를 랜덤 값을 주고, 텍스트를 value로 줘서 단어별로 카운트를 한다.
해당 출력을 시스템이 모아서, 같은 키를 같는 레코드들을 하나의 레코드로 묶어서 reduce의 입력으로 넣는다.
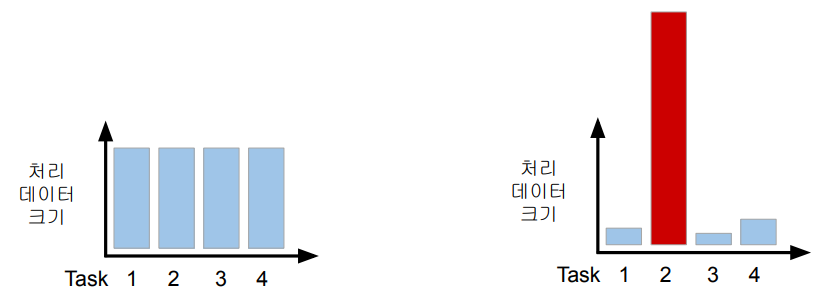
이 과정에서 셔플링이 발생하는데, 특정 리듀스로 데이터가 너무 몰리는 data skew가 발생한다.
Map 코드
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
Reduce 코드
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}