
1. SPARK ML 소개
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- Classification, Regression, Clustering, Collaborative Filtering, Dimensionality Reduction
- 아직 딥러닝 지원은 미약
- https://spark.apache.org/docs/latest/ml-classification-regression.html
- 여기에는 RDD 기반과 데이터프레임 기반의 두 버전이 존재
- spark.mlib vs. spark.ml
- spark.mlib가 RDD 기반이고 spark.ml은 데이터프레임 기반
- spark.mlib는 RDD 위에서 동작하는 이전 라이브러리로 더 이상 업데이트가 안됨
- 항상 spark.ml을 사용할 것!
- import pyspark.ml
- spark.mlib vs. spark.ml
Classification and regression - Spark 3.4.1 Documentation
spark.apache.org
- Spark ML의 장점
- 원스톱 ML 프레임워크
- 데이터프레임과 SparkSQL등을 이용해 전처리
- Spark MLlib을 이용해 모델 빌딩
- ML Pipeline을 통해 모델빌딩 자동화
- MLflow로 모델 관리하고 서빙
- 대용량 데이터도 처리 가능!
- 데이터가 작을 경우엔, pandas, 사이킷런으로 충분하다.
- 원스톱 ML 프레임워크
- Spark ML 소개 : MLflow
- 모델의 관리와 서빙을 위한 Ops 관련 기능도 제공
- MLflow
- 모델 개발과 테스트와 관리와 서빙까지 제공해주는 End-to-End 프레임워크
- MLflow는 파이썬, 자바, R, API를 지원
- MLflow는 트래킹(Tracking), 모델(Models), 프로젝트(Projects)를 지원
- Spark ML 제공 알고리즘
- Classification :
- Logistic Regression, Decision tree, Random forest, Gradient-boosted tree, ...
- Regression :
- Linear Regression, Decision tree, Random forest, Gradient-boosted tree, ...
- Clustering :
- K-means, LDA(Latent Dirichlet Allocation), GMM(Gaussian Mixture Model), ...
- Collaborative Filtering
- 명시적인 피드백과 암묵적인 피드백 기반
- 명시적인 피드백의 예) 리뷰 평점
- 암묵적인 피드백의 예) 클릭, 구매 등등
- Classification :
2. 실습 소개
- 보스턴 주택가격 예측 모델 만들기 : Regression
- 타이타닉 승객 생존 예측 모델 만들기 : Classification
- Spark ML 기반 모델 빌딩의 기본 구조
- 어느 라이브러리를 사용한 모델 빌딩과 크게 다르지 않음
- 트레이닝셋 전처리
- 모델 빌딩
- 모델 검증(confusion matrix)
- Scikit-Learn과 비교했을 때 장점
- 차이점은 결국 데이터의 크기
- Scikit-Learn은 하나의 컴퓨터에서 돌아가는 모델 빌딩
- Spark MLlib은 여러 서버 위에서 모델 빌딩
- 트레이닝셋의 크기가 크면 전처리와 모델 빌딩에 있어 Spark이 큰 장점을 가짐
- Spark은 ML 파이프라인을 통해 모델 개발의 반복을 쉽게 해줌
- 차이점은 결국 데이터의 크기
- 어느 라이브러리를 사용한 모델 빌딩과 크게 다르지 않음
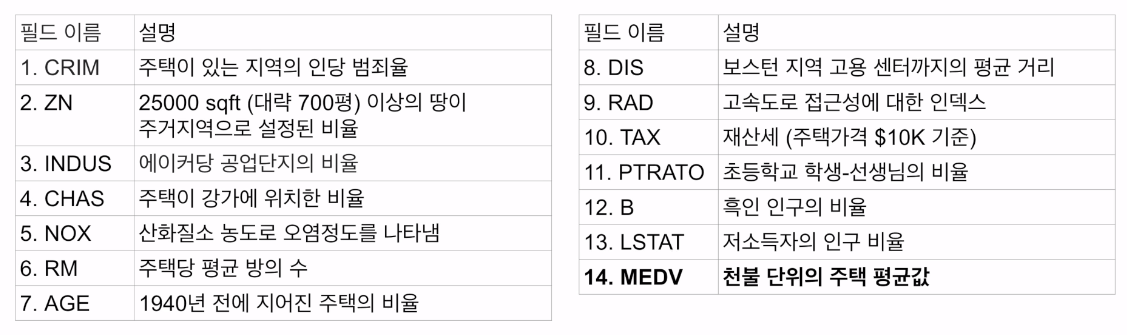
3. 보스턴 주택가격 예측
- 1970년대 미국 인구조사 서비스 (US Census Service)에서 보스턴 지역의 주택 가격 데이터를 수집한 데이터를 기반으로 모델 빌딩
- 개별 주택 가격의 예측이 아니라 지역별 중간 주택가격 예측
- Regression 알고리즘 사용
- 연속적인 주택 가격 예측이기에 Classification 알고리즘 사용 불가
- 총 506개의 레코드로 구성되며 13개의 피쳐와 레이블 필드(주택가격)으로 구성
- 506개 동네의 주택 중간값 데이터임 (개별 주택이 아님에 유의)
- 14번째 필드가 바로 예측해야하는 중간 주택 가격
4. 타이타닉 승객 생존 예측
- 머신러닝의 Hello World라고 할 수 있는 굉장히 유명한 데이터셋
- 2015년 캐글에서 "Titanic - Machine Learning from Diaster"라는 이름의 튜토리얼로 시작됨
- Binary Classification 알고리즘 사용 예정
- 생존 혹은 비생존을 예측하는 것이라 Binary Classfication을 사용
- 정확히는 Binomial Logistic Regression을 사용(2개의 클래스 분류기)
- AUC(Area Under the Curve)의 값이 중요한 성능 지표가 됨
- True Positive Rate과 False Positive Rate
- True Positive Rate : 생존한 경우를 얼마나 맞게 예측했나? 흔히 Recall이라고도 부르기도함
- False Positive Rate : 생존하지 못한 경우를 생존한다고 얼마나 예측했나?
- True Positive Rate과 False Positive Rate
- 총 892개의 레코드로 구성되며 11개의 피쳐와 레이블 필드(생존여부)로 구성
- 2번째 필드(Survived) 바로 예측해야하는 승객 생존 여부

'데이터 엔지니어링 > Spark' 카테고리의 다른 글
| 29. SparkML(Classification, 타이타닉 생존 예측 모델) (0) | 2023.08.25 |
|---|---|
| 28. Spark ML(Regression, 보스턴 주택값 예측 모델) (0) | 2023.08.23 |
| 26. Spark 내부 동작(Bucketing과 Partitioning) (0) | 2023.08.23 |
| 25. Spark 내부 동작(Execution Plan 실습, Spark Web UI) (0) | 2023.08.22 |
| 24. Spark 내부 동작(Execution Plan) (0) | 2023.08.22 |
1. SPARK ML 소개
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- Classification, Regression, Clustering, Collaborative Filtering, Dimensionality Reduction
- 아직 딥러닝 지원은 미약
- https://spark.apache.org/docs/latest/ml-classification-regression.html
- 여기에는 RDD 기반과 데이터프레임 기반의 두 버전이 존재
- spark.mlib vs. spark.ml
- spark.mlib가 RDD 기반이고 spark.ml은 데이터프레임 기반
- spark.mlib는 RDD 위에서 동작하는 이전 라이브러리로 더 이상 업데이트가 안됨
- 항상 spark.ml을 사용할 것!
- import pyspark.ml
- spark.mlib vs. spark.ml
Classification and regression - Spark 3.4.1 Documentation
spark.apache.org
- Spark ML의 장점
- 원스톱 ML 프레임워크
- 데이터프레임과 SparkSQL등을 이용해 전처리
- Spark MLlib을 이용해 모델 빌딩
- ML Pipeline을 통해 모델빌딩 자동화
- MLflow로 모델 관리하고 서빙
- 대용량 데이터도 처리 가능!
- 데이터가 작을 경우엔, pandas, 사이킷런으로 충분하다.
- 원스톱 ML 프레임워크
- Spark ML 소개 : MLflow
- 모델의 관리와 서빙을 위한 Ops 관련 기능도 제공
- MLflow
- 모델 개발과 테스트와 관리와 서빙까지 제공해주는 End-to-End 프레임워크
- MLflow는 파이썬, 자바, R, API를 지원
- MLflow는 트래킹(Tracking), 모델(Models), 프로젝트(Projects)를 지원
- Spark ML 제공 알고리즘
- Classification :
- Logistic Regression, Decision tree, Random forest, Gradient-boosted tree, ...
- Regression :
- Linear Regression, Decision tree, Random forest, Gradient-boosted tree, ...
- Clustering :
- K-means, LDA(Latent Dirichlet Allocation), GMM(Gaussian Mixture Model), ...
- Collaborative Filtering
- 명시적인 피드백과 암묵적인 피드백 기반
- 명시적인 피드백의 예) 리뷰 평점
- 암묵적인 피드백의 예) 클릭, 구매 등등
- Classification :
2. 실습 소개
- 보스턴 주택가격 예측 모델 만들기 : Regression
- 타이타닉 승객 생존 예측 모델 만들기 : Classification
- Spark ML 기반 모델 빌딩의 기본 구조
- 어느 라이브러리를 사용한 모델 빌딩과 크게 다르지 않음
- 트레이닝셋 전처리
- 모델 빌딩
- 모델 검증(confusion matrix)
- Scikit-Learn과 비교했을 때 장점
- 차이점은 결국 데이터의 크기
- Scikit-Learn은 하나의 컴퓨터에서 돌아가는 모델 빌딩
- Spark MLlib은 여러 서버 위에서 모델 빌딩
- 트레이닝셋의 크기가 크면 전처리와 모델 빌딩에 있어 Spark이 큰 장점을 가짐
- Spark은 ML 파이프라인을 통해 모델 개발의 반복을 쉽게 해줌
- 차이점은 결국 데이터의 크기
- 어느 라이브러리를 사용한 모델 빌딩과 크게 다르지 않음
3. 보스턴 주택가격 예측
- 1970년대 미국 인구조사 서비스 (US Census Service)에서 보스턴 지역의 주택 가격 데이터를 수집한 데이터를 기반으로 모델 빌딩
- 개별 주택 가격의 예측이 아니라 지역별 중간 주택가격 예측
- Regression 알고리즘 사용
- 연속적인 주택 가격 예측이기에 Classification 알고리즘 사용 불가
- 총 506개의 레코드로 구성되며 13개의 피쳐와 레이블 필드(주택가격)으로 구성
- 506개 동네의 주택 중간값 데이터임 (개별 주택이 아님에 유의)
- 14번째 필드가 바로 예측해야하는 중간 주택 가격
4. 타이타닉 승객 생존 예측
- 머신러닝의 Hello World라고 할 수 있는 굉장히 유명한 데이터셋
- 2015년 캐글에서 "Titanic - Machine Learning from Diaster"라는 이름의 튜토리얼로 시작됨
- Binary Classification 알고리즘 사용 예정
- 생존 혹은 비생존을 예측하는 것이라 Binary Classfication을 사용
- 정확히는 Binomial Logistic Regression을 사용(2개의 클래스 분류기)
- AUC(Area Under the Curve)의 값이 중요한 성능 지표가 됨
- True Positive Rate과 False Positive Rate
- True Positive Rate : 생존한 경우를 얼마나 맞게 예측했나? 흔히 Recall이라고도 부르기도함
- False Positive Rate : 생존하지 못한 경우를 생존한다고 얼마나 예측했나?
- True Positive Rate과 False Positive Rate
- 총 892개의 레코드로 구성되며 11개의 피쳐와 레이블 필드(생존여부)로 구성
- 2번째 필드(Survived) 바로 예측해야하는 승객 생존 여부
'데이터 엔지니어링 > Spark' 카테고리의 다른 글
| 29. SparkML(Classification, 타이타닉 생존 예측 모델) (0) | 2023.08.25 |
|---|---|
| 28. Spark ML(Regression, 보스턴 주택값 예측 모델) (0) | 2023.08.23 |
| 26. Spark 내부 동작(Bucketing과 Partitioning) (0) | 2023.08.23 |
| 25. Spark 내부 동작(Execution Plan 실습, Spark Web UI) (0) | 2023.08.22 |
| 24. Spark 내부 동작(Execution Plan) (0) | 2023.08.22 |