from pyspark.sql import SparkSession
from pyspark.sql.functions import col
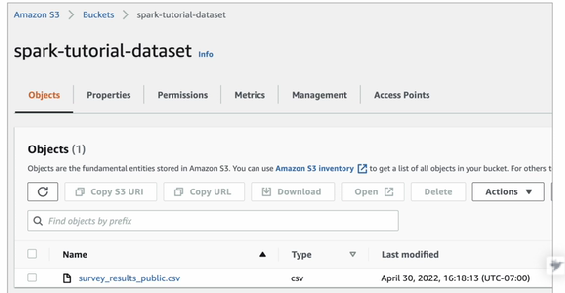
S3_DATA_INPUT_PATH = 's3://spark-tutorial-dataset/survey_result_public.csv'
S3_DATA_OUTPUT_PATH = 's3://spark-tutorial-dataset/data-output'
spark = SparkSession.builder.appName('Tutorial').getOrCreate()
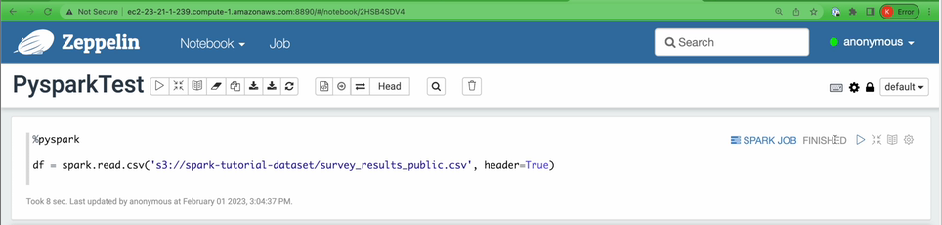
df = spark.read.csv(S3_DATA_INPUT_PATH, header = True)
print('# of records {}'.format(df.count()))
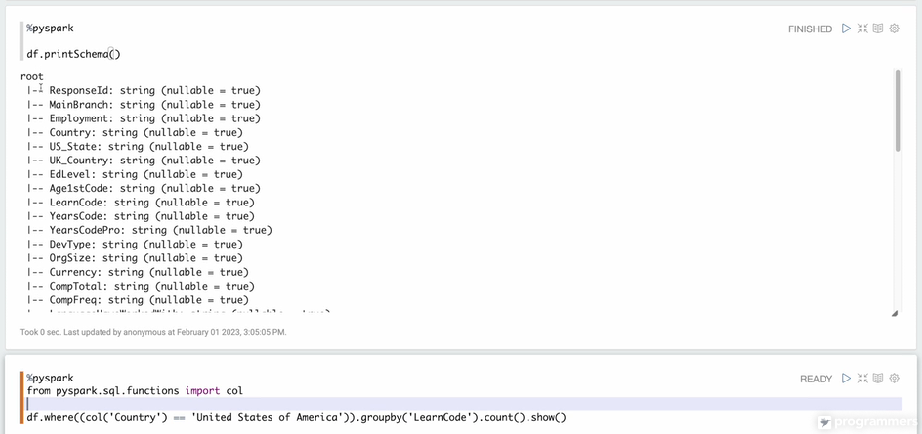
learnCodeUS = df.where((col('Country') == 'United States of America')).groupby('LearnCode').count()
learnCodeUs.write.mode('overwrite').csv(S3_DATA_OUTPUT_PATH) # parquet
learnCodeUs.show()
print('Selected data is successfully saved to S3 : {}'.format(S3_DATA_OUTPUT_PATH)
SparkSQL 버전
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
S3_DATA_INPUT_PATH = 's3://spark-tutorial-dataset/survey_result_public.csv'
S3_DATA_OUTPUT_PATH = 's3://spark-tutorial-dataset/data-output'
spark = SparkSession.builder.appName('Tutorial').getOrCreate()
df = spark.read.csv(S3_DATA_INPUT_PATH, header = True)
print('# of records {}'.format(df.count()))
# 임시테이블 생성
df.createOrReplaceTempView("stackoverflow")
learnCodeUS = spark.sql("""
SELECT LearnCode, COUNT(1) count
FROM stackoverflow
WHERE Country = 'United States of America'
GROUP BY 1""")
# learnCodeUS = df.where((col('Country') == 'United States of America')).groupby('LearnCode').count()
learnCodeUs.write.mode('overwrite').csv(S3_DATA_OUTPUT_PATH) # parquet
learnCodeUs.show()
print('Selected data is successfully saved to S3 : {}'.format(S3_DATA_OUTPUT_PATH)
2. Spark 마스터 노드에 ssh로 로그인하여 spark-submit을 통해 실행
앞서 다운로드 받은 .pem 파일을 사용하여 SSH 로그인
spark-submit --master yarn stackoverflow.py
잡 실행결
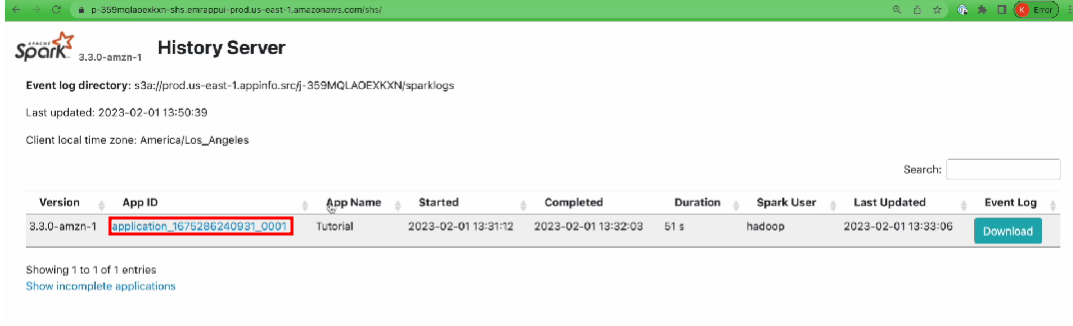
3. EMR Spark Cluster Web UI 확인
DataFrame Version
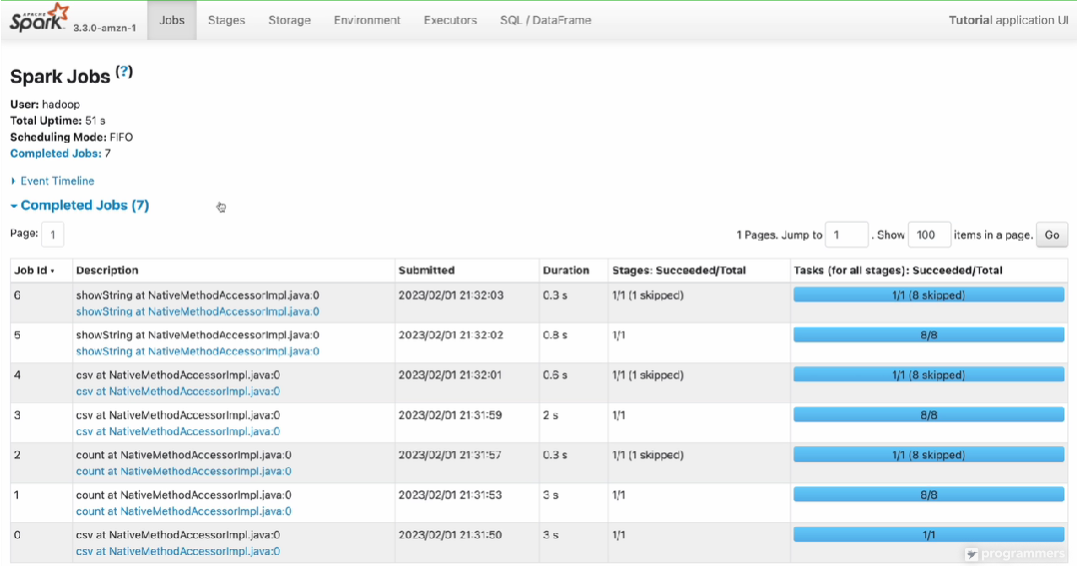
웹화면클릭시 jobs(DataFrame Version)
7개의 Job으로 구성, 각 Job은 Stage 하나로 구성
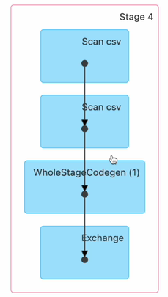
Execution Plan(DataFrame Version)
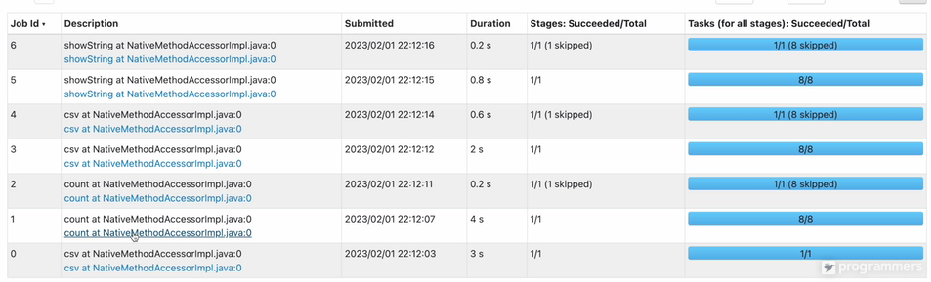
SQL Version
Job 7개(Dataframe과 별 차이 없었음)
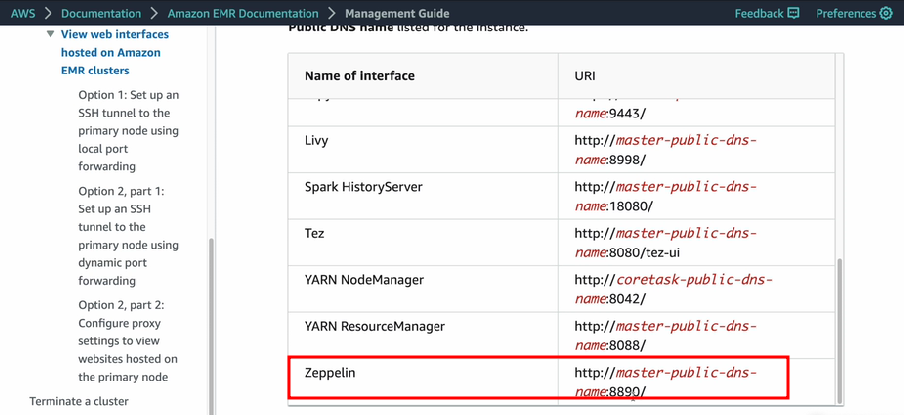
EMR 클러스터의 Zeppelin
(1) ZeppelinACCESS ON EMR
Yarn에도 node 매니저 뿐만 아니라, 다양한 웹 UI가 있다.
이런 것들은 SSH CONNECTION을 ENABLE 해야 ACCESS 할 수 있게 되어있다.
SSH 터널링
크롬에선 EXTENSION 받아서 Configuration을 끝내야한다.
두 단계 작업 후, 맨 아래 링크 클릭
링크에서 포트번호 확인 후 내 작업 브라우저에서 ACCESS
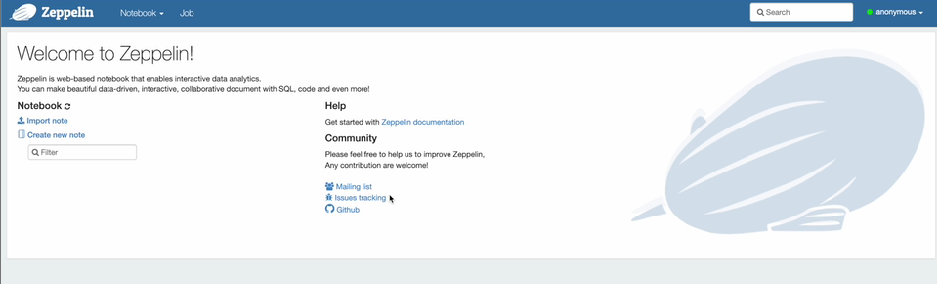
(2) Zeppelin 사용
Python, R, Scala를 이용해서 Spark과 Interactive하게 코딩할 수 있는 Notebook