
Seaborn이란
Seaborn은 Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지입니다.
기본적인 시각화 기능은 Matplotlib 패키지에 의존하며 통계 기능은 Statsmodels 패키지에 의존합니다.
테마를 활용해서 스타일 적용하기
set_theme()는 global 범위의 테마를 적용해서 그래프를 쉽게 꾸밀 수 있습니다. style과 palette 키워드 인수를 활용해서 그 값을 설정합니다.
- style : darkgrid, whitegrid, dark, white, ticks, ...
- palette : pastel, husl, Spectral, flare, ... (참고) set_context()의 인수로 paper, notebook, talk, poster 중 하나를 넣으면 해당하는 설정을 세팅할 수 있습니다.
import seaborn as sns sns.set_theme(style = 'whitegrid')
카운트 플롯(Countplot)
countplot()을 사용하면 각 카테고리 값마다의 데이터가 얼마나 있는지 표시할 수 있습니다.
카운트 플롯은 카테고리별 히스토그램이라고 볼 수 있습니다. API와 옵션은 바 차트와 동일합니다.
타이타닉호의 데이터셋을 활용해서 카운트 플롯을 확인해보겠습니다. class는 선실의 등급을 나타내는 column입니다.
마치 value_counts()의 결과를 보듯한 바 차트를 볼 수 있습니다. 각 유니크한 값들이 몇개씩 있는지 시각적으로 확인 가능합니다.
# Show the number of datapoints with each value of a categorical variable
df = sns.load_dataset('titanic')
sns.countplot(x = df['class']) # 시리즈를 인수로
# x 키워드 인수에 시리즈를 전달하고 있습니다. 해당 시리즈에 있는 값을 유니크하게 가져와서 카운트한 결과를 가져오는 것을 확인할 수 있습니다.
hue 키워드 인수를 활용하여 분류할 두번째 변수를 설정할 수 있습니다. 여기서는 alive를 column으로 지정하였고 선신별 생존여부를 가시적으로 확인할 수 있게 돕고 있습니다.

# Group by a second variable
sns.countplot(data = df, x = "class", hue = 'alive')여기서는 data 키워드 인수에 DataFrame을 전달하고 x 키워드 인수에 DataFrame 중 매칭하고 싶은 column의 name 값을 전달하고 있습니다.
뿐만 아니라 hue 키워드 인수에도 DataFrame의 column name을 전달하고 있음을 주목하세요.
# Group by a second variable
sns.countplot(data = df, x = "class", hue = "alive")플롯을 수평하게도 작성할 수 있습니다. y 키워드 인수에 data로 넘긴 DataFrame의 column name 값을 전달하면 됩니다.
아래 예제에서는 그래프를 수평하게 표현하여 카테고리 레이블을 나타내는 legend(범례) 공간을 확보했습니다.
# Plot horizontally to make more space for category value
sns.countplot(data = df, y = 'deck', hue = 'alive')tips 데이터셋
- total_bill : 총 지불금액
- tip : 팁
- sex : 성별
- smoker : 흡연여부
- day : 요일
- time : 식사 시간대
- size : 식사 인원
rugplot()
러그(rug) 플롯은 데이터 위치를 x축 위에 작은 선분(rug)으로 나타내어 실제 데이터들의 위치를 보여준다.
커널 밀도(kernel density)는 커널이라는 함수를 겹치는 방법으로 히스토그램보다 부드러운 형태의 분포 곡선을 보여줍니다.
sns.kdeplot(data = tips, x = 'total_bill')
sns.rugplot(data = tips, x = 'total_bill')
# Add a rug alon both axes
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip')
sns.rugplot(data = tips, x = 'total_bill', y = 'tip')
# Add a rug alon both axes, hue 추가
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'time')
sns.rugplot(data = tips, x = 'total_bill', y = 'tip', hue = 'time', height = .1)
diamonds = sns.load_dataset('diamonds')
sns.scatterplot(data = diamonds, x = 'carat', y = 'price', s = 5)
sns.rugplot(data = diamonds, x = 'carat', y = 'price', lw = 1, alpha = 0.05)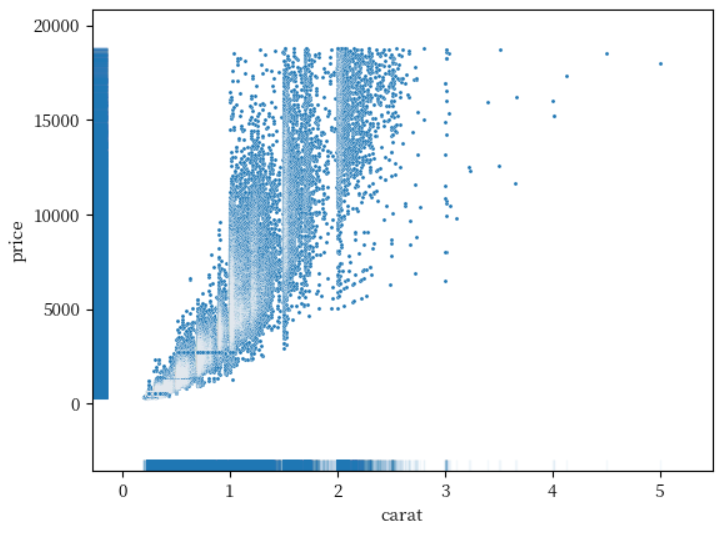
히스토그램(histogram)
히스토그램은 1차원 혹은 2차원 데이터 분포를 시각화합니다.
# 'Adelie', 'Chinstrap', 'Gentoo' 3가지 펭귄에 대한 데이터입니다.
penguins = sns.load_dataset('penguins')
penguins.head()
# species: 펭귄의 종(Chinstrap, Adélie, Gentoo)
# culmen_length_mm: culmen length (mm)
# culmen_depth_mm: culmen depth (mm)
# flipper_length_mm: flipper length (mm)
# body_mass_g: 체중(g)
# island: 서식지 섬 (Dream, Torgersen, or Biscoe) in the Palmer Archipelago (Antarctica)
# sex: 펭귄 성별히스토그램 - histplot() x축 기준
flipper 길이에 대한 분포를 x축 기준으로 히스토그램을 나타내는 예제입니다.
data로 DataFrame을 전달하고 x 키워드 인수로 columns label 값을 전달하고 있습니다.
히스토그램을 보면 좌측 y축 개수를 표현하고 있습니다.
sns.histplot(data = penguins, x = 'flipper_length_mm')
히스토그램 - histplot() y축 기준
y축을 기준으로 히스토그램을 포현하고 있습니다. x 키워드 인수를 y 키워드 인수로 변경하여 표현했습니다.
sns.histplot(data = penguins, y = 'flipper_length_mm')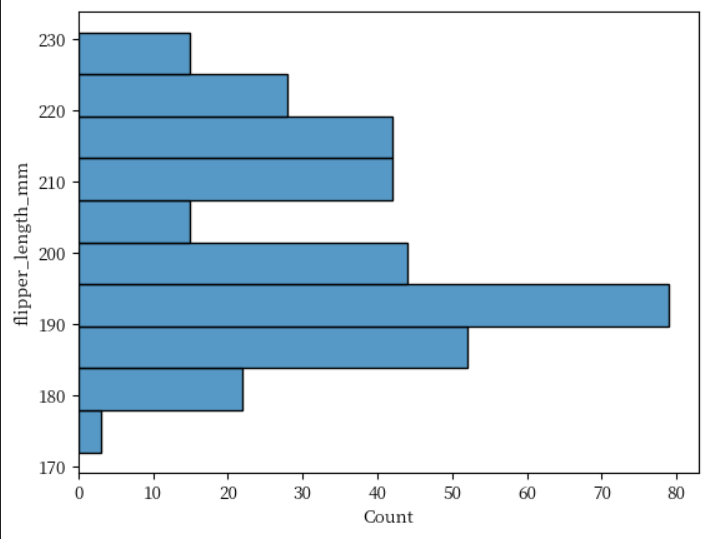
히스토그램 - histplot() bin 너비 지정하기
binwidth 키워드 인수를 사용하면 bin의 너비를 지정할 수 있습니다. 현재는 3으로 값을 줘서 3의 범위만큼
히스토그램이 표현되는 것을 확인할 수 있습니다.
sns.histplot(data = penguins, x = 'flipper_length_mm', binwidth = 3)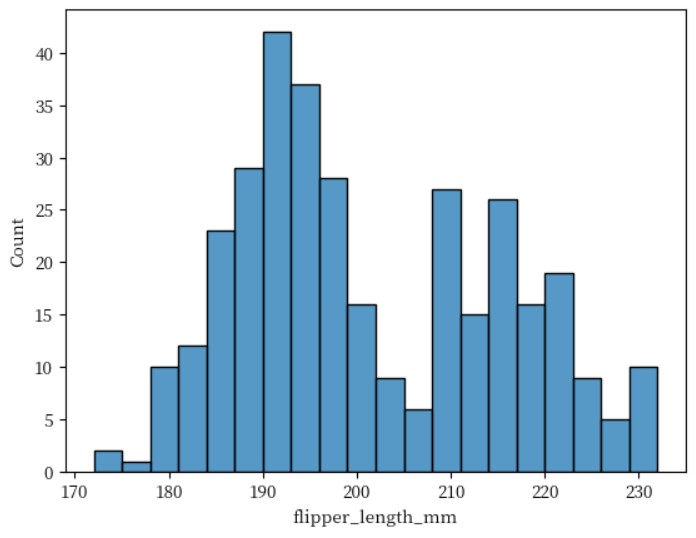
히스토그램 - histplot() bin 개수 지정하기
bins 키워드 인수를 사용해서 bin 개수를 지정할 수도 있습니다. 아래에서는 30개의 bin을 만들고 이를 히스토그램으로
출력하고 있습니다.
sns.histplot(data = penguins, x = 'flipper_length_mm', bins = 30)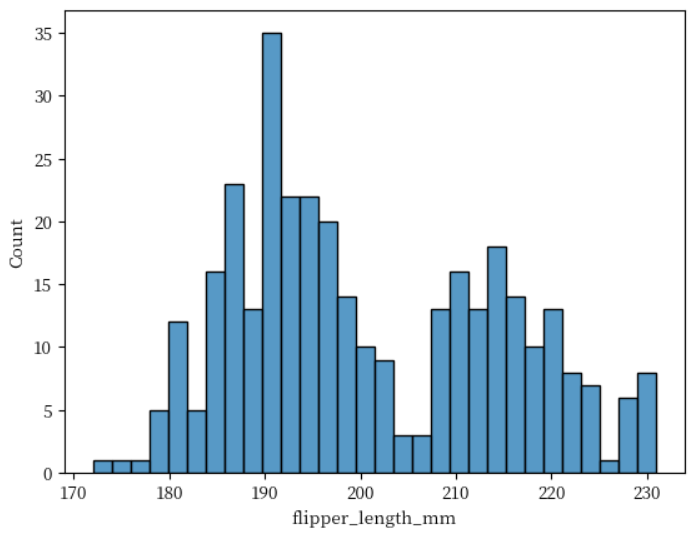
히스토그램 - histplot() kde를 동시에 표시하기
kde는 Kernel density의 약자로 커널이라는 함수를 겹치는 방법으로 히스토그램보다 부드러운 형태의 분포 곡선을 보여줍니다.
아래 코드에서는 kde 키워드 인수에 True 값을 전달하여 히스토그램과 kde 그래프를 동시에 출력하고 있습니다.
sns.histplot(data = penguins, x = 'flipper_length_mm', kde = True)
히스토그램 - histplot() hue 키워드 인수로 데이터 분리하기
hue 키워드 인수에 분류 기준이 될 column label을 전달해서 여러개의 히스토그램을 합친 것과 같은 결과의 그래프를 얻을 수 있습니다. 펭귄의 종류마다 분포를 나눴기 대문에 이제야 분포가 명확하게 보이는 것을 확인할 수 있습니다
sns.histplot(data = penguins, x = 'flipper_length_mm', hue = 'species')
히스토그램 - hisplot() 다양한 표현법 stack
앞서 살펴봤던 예제는 각 히스토그램의 layer가 겹쳐서 표현됐다면 이를 누적하듯 표현하는 방법도 있습니다.
multiple 키워드 인수에 'stack' 값을 전달하면 됩니다. 펭귄의 종류별 누적 히스토그램을 아래와 같이 확인할 수 있습니다.
sns.histplot(data = penguins, x = 'flipper_length_mm', hue = 'species', multiple = 'stack')
히스토그램 - histplot() 다양한 표현법 step
오버래핑된 결과가 보기 힘들 때의 해결 방법 중 하나로 elements 키워드 인수에 'step'이란 값을 전달하여 아래의 그림처럼 표현할 수 있습니다.
sns.histplot(penguins, x = 'flipper_length_mm', hue = 'species', element = 'step')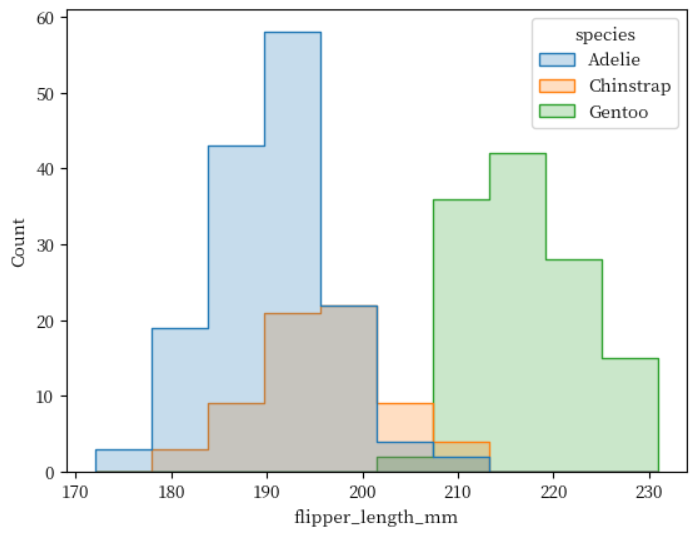
히스토그램 - histplot()의 다양한 표현법 poly
다각형 형태로도 표현 가능합니다. element 키워드 인수에 'poly' 값을 전달하면 됩니다.
이는 전체적인 모양을 살피는데에 유용합니다.
sns.histplot(penguins, x = 'flipper_length_mm', hue = 'species', element = 'poly')
x축과 y축 모두 column을 할당하게 되면 히트맵(heatmap) 형태의 히스토그램을 표현합니다.
sns.histplot(penguins, x = 'bill_depth_mm', y = 'body_mass_g' ,hue = 'species', element = 'poly')
x축과 y축 모두 column을 할당할 때 그 중 하나의 값이 이산된 값이라면 아래와 같이 데이터를 시각화하여 표현하면 훨씬 이해가 쉽게 표현할 수 있습니다.
sns.histplot(penguins, x = 'bill_depth_mm', y= 'species', hue = 'species', legend = False)
히스토그램 - distplot()
displot()도 마찬가지로 1차원 혹은 2차원 데이터의 분포를 히스토그램으로 보여줍니다.
다만 rug와 kde에 대해 동시에 표현이 가능해서 표현범위가 더 넓고 이에 따라 많이 사용됩니다.
기본적인 형태의 히스토그램을 그리고 있습니다. histplot()과 동일한 인수와 그래프 모양을 보여줍니다.
sns.displot(data = penguins, x = 'flipper_length_mm')
kind 키워드 인수를 활용해서 기본적으로 표현되는 히스토그램의 종류를 kde로 변경했습니다.
sns.displot(data = penguins, x = 'flipper_length_mm', kind = 'kde')
이번에는 kind 키워드 인수에 ecdf(empirical cumulative distribution functions)를 활용해서 누적 분포 그래프로 표현하고 있습니다.
sns.displot(data = penguins, x = 'flipper_length_mm', kind = 'ecdf')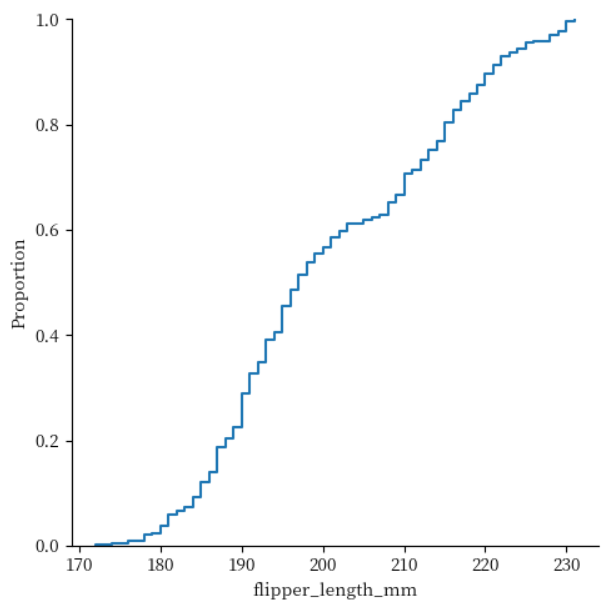
kde 키워드 인수 값을 True로 전달하여 히스토그램과 kde를 동시에 표현하고 있습니다.
앞에서의 kind = kde와 비교해서 차이점을 생각해보세요
sns.displot(data = penguins, x = 'flipper_length_mm', kde = True)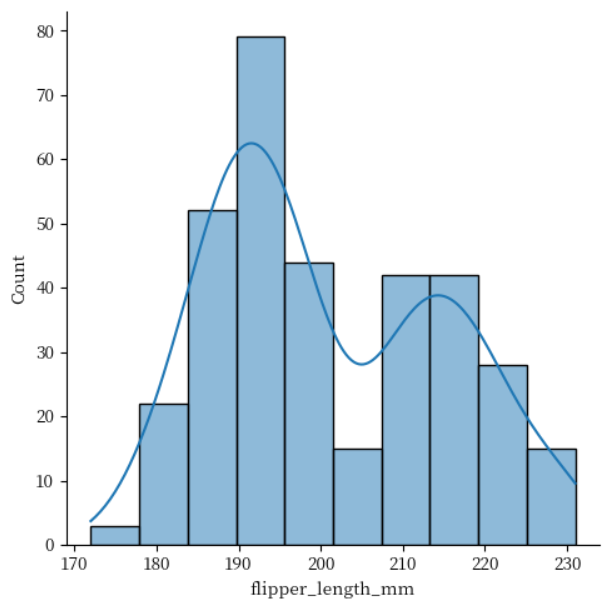
히스토그램 - displot() x, y 모두 값 할당하기
histplot()과 동일하게 x와 y에 각각 값을 할당하여 히트맵 형태로 그래프를 출력할 수 있습니다.
sns.displot(data = penguins, x = 'flipper_length_mm', y = 'bill_length_mm', hue = 'species')
히스토그램 displot 2개 값을 kde로 표현하기
x축 y축 모두할당한 앞의 히스토그램을 kde로도 표현가능합니다. 뿐만 아니라 rug = True 키워드 인수를 전달해서
rug에 대한 표현도 동시에 할 수 있습니다.
sns.displot(data = penguins, x = 'flipper_length_mm', y = 'bill_length_mm', kind = 'kde', rug = True)
히스토그램 - displot() hue로 subset 나누기
hue 키워드 인수를 통해 subset을 구분하고 이를 각각의 그래프로 표현할 수 있습니다.
아래는 hue 값으로 species(펭귄의 종)에 대해 설정해서 각각 species 별로 그래프를 만들었습니다.
**히스토그램 - displot col로 그래프 나누기**-
displot()은 더 나아가 col 키워드 인수를 활용하여 subset을 한번 더 분류할 수있습니다. col에 sex column label을 설정하여 subset을 이전 예제보다 더 나눴습니다.
sns.displot(data = penguins, x = 'flipper_length_mm', hue = 'species', col = 'sex', kind = 'kde')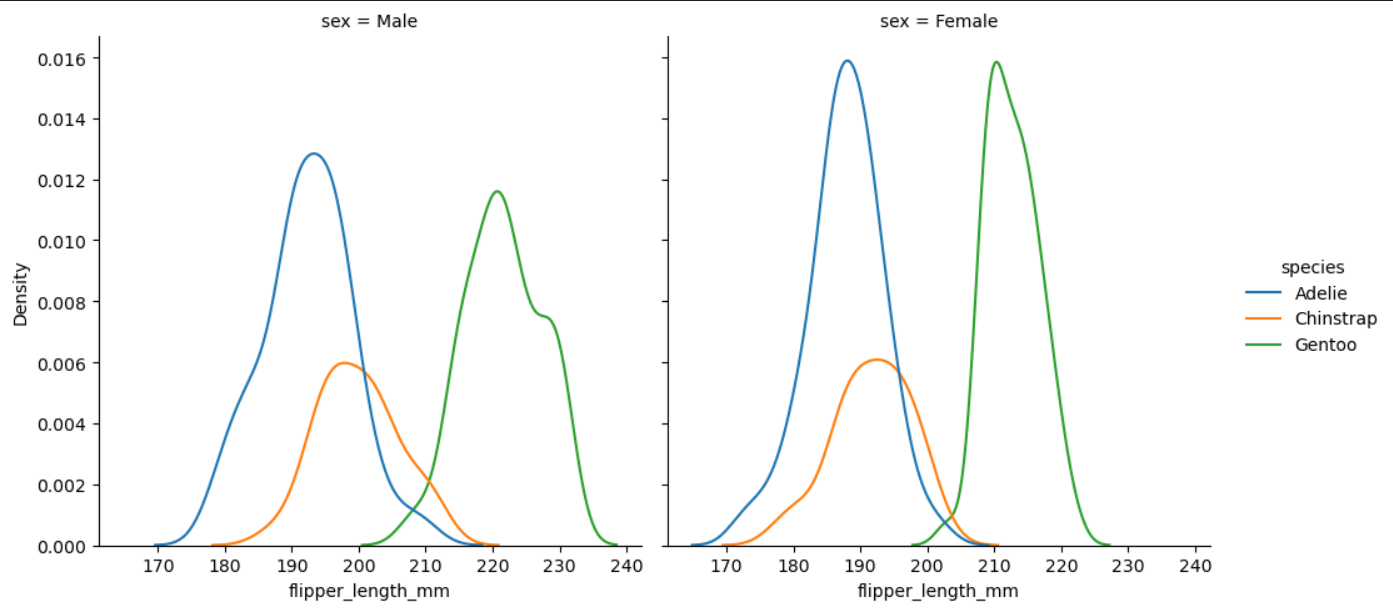
히스토그램 - displot() 그래프 크기 설정
height와 aspect를 활용해서 그래프 크기를 제어할 수 있습니다. height의 단위는 inches이며 aspect는 height와 aspect 값을 곱해서 얻습니다. 높이 대비 너비 비율을 지정한다고 이해하면 됩니다.
sns.displot(
data = penguins, y = 'flipper_length_mm', hue = 'sex', col = 'species',
kind = 'ecdf', height = 4, aspect = .7)
각 axis label과 title도 지정해줄 수 있습니다. axis label은 set_axis_labels(xlabel, ylabel) 메서드를, title은 set_titles()을 활용하는데, formatting keys인 {col_var}와 {col_name}을 조합해서 포맷팅할 수 있습니다.
g = sns.displot(
data = penguins, y = 'flipper_length_mm', hue = 'sex', col = 'species',
kind = 'kde', height = 4, aspect = .7)
g.set_axis_labels("Density (a.u.)", "Flipper length (mm)")
g.set_titles('{col_name} penguins')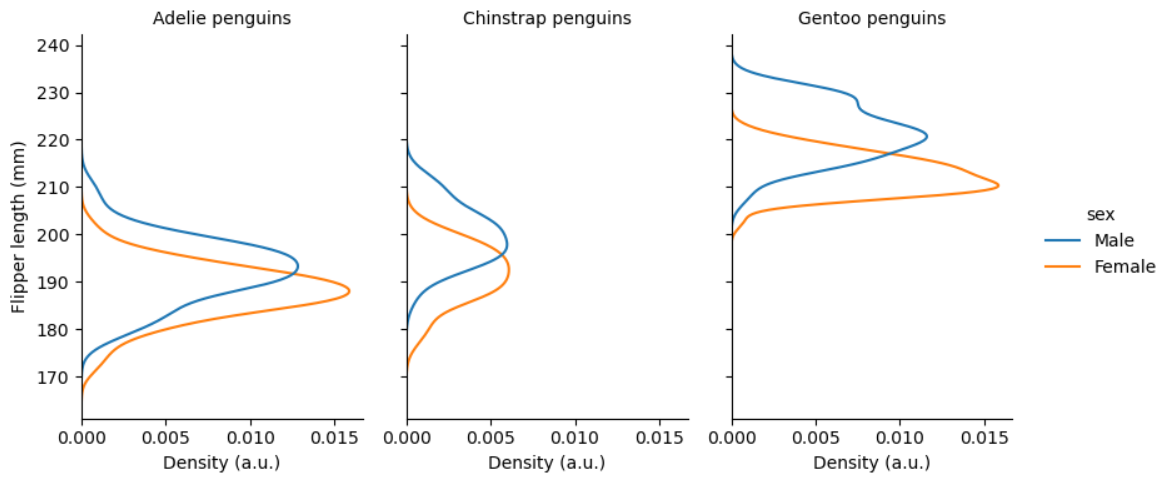
'데이터 분석 및 시각화 > 데이터 시각화' 카테고리의 다른 글
| [Python] Seaborn(stripplot, swarmplot, catplot, jointplot, pairplot, Pandas pivot table), Pandas Pivot table (0) | 2023.01.27 |
|---|---|
| [Python] Seaborn(barplot, boxplot, violinplot) (0) | 2023.01.27 |
| [Python] matplotlib - 차트 (0) | 2023.01.26 |
| [Python] Matplotlib - 폰트 설정법 (0) | 2023.01.26 |
| [Python] Matplotlib - Figure, Axes, Axis, Artist (0) | 2023.01.26 |