
빅데이터의 정착
- 기본 구조
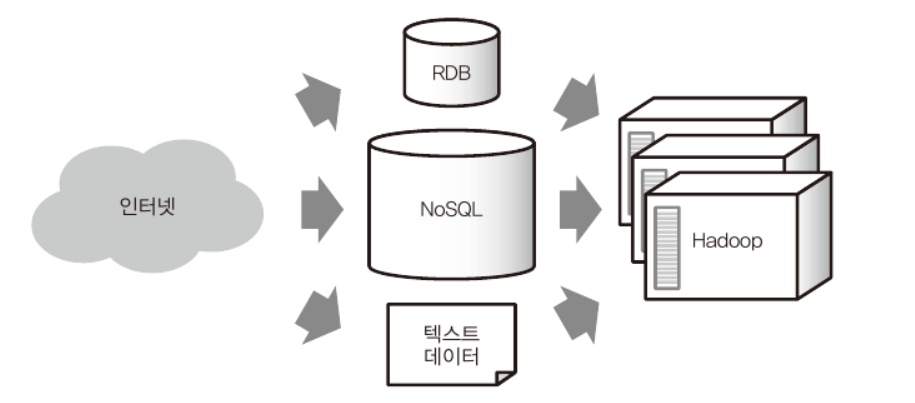
- 웹 서버 등에서 생성된 데이터는 처음에는 RDB 혹은 NOSQL 등의 텍스트 데이터에 저장. 그 후 모든 데이터가 HADOOP으로 모이고, 거기서 대규모 데이터 처리가 실행된다
HADOOP : 다수의 컴퓨터에서 대량의 데이터 처리
- 예를 들어 전 세계 웹페이지를 모아서 검색엔진을 만들려면 방대한 데이터를 저장해둘 스토리지와 데이터를 순차적으로 처리할 수 있는 구조가 필요.
- 그러기 위해선 수백, 수천대 단위의 컴퓨터가 이용되어야하는데, 이것을 관리하는 프레임워크가 Hadoop
- 하둡은 구글에서 개발된 분산처리 프레임워크인" MapReduce"를 참고하여 제작됨(이후 Aparch Spark가 이를 대체하는 추세)
- SQL 같은 쿼리언어를 하둡에서 실행하기 위한 소프트웨어로 "Hive(하이브)"가 개발 되어 출시
NOSQL 데이터베이스
- RDB에 비해 고속의 읽기/쓰기 및 분산 처리가 강점
- 전통적인 RDB 제약을 제거하는 것을 목표로한 데이터베이스의 총칭
- 종류
- 키밸류 스토어
- 도큐멘트 스토어
- 와이드 칼럼 스토어
- 하둡과 다르게 NOSQL은 애플리케이션에서 온라인으로 접속하는 데이터베이스
HADOOP과 NOSQL 데이터베이스의 조합 : 현실적인 비용으로 대규모 데이터 처리 실현
- NOSQL 데이터베이스에 기록하고
- Hadoop으로 분산 처리하기
데이터웨어하우스
- 일부 기업에서는 이전부터 데이터 분석을 기반으로 하는 '엔터프라이즈 데이터 웨어하우스' 도입
- 데이터 웨어하우스에서도 대량의 데이터처리는 가능하나, 안정적인 성능 실현을 위해 하드웨어/소프트웨어가 통합된 장비로 제공되었었음.
- 따라서 가속도적으로 늘어나는 데이터 처리가 어려웠는데, 이걸 HADOOP에 맡기면서 이 둘을 동시에 사용
- 중요 데이터는 여전히 데이터 웨어하우스에 밀어넣는 식
- 야간 배치 등 심야에 대량으로 발생하는 데이터 처리에 HADOOP 사용, 야간 배치에서는 매일 거래되는 데이터 등을 심야에 집계하여 다음날 아침까지 보고서에 정리
- 데이터 양이 증가하면 배치 처리 또한 시간이 걸려, 보고서의 완성이 늦어지고, 이로 인해 업무에 지장이 생긴다.
- 따라서 확장성이 뛰어난 하둡에 데이터처리를 맡겨 데이터웨어하우스의 부하를 줄인다.

클라우드 서비스
| 이벤트 | 서비스의 특징 |
|---|---|
| 아마존 Elastic MapReduce | 클라우드를 위한 Hadoop |
| 구글 BigQuery | 데이터 웨어하우스 |
| Azure HDInsight | 클라우드를 위한 Hadoop |
| Amazon Redshift | 데이터 웨어하우스 |
- 아마존 레드시프트 발표이후 작은 프로젝트 단위에서도 자체적으로 데이터웨어하우스를 구축하여 데이터 분석기반을 마련할 수 있게됨
데이터 디스커버리 기술 : 셀프 서비스용 BI 도구
- 빅데이터 기술 이후 데이터웨어하우스에 저장된 데이터를 시각화하려는 방법으로 '데이터 디스커버리(Data Discvoery)가 인기 끌게됨
- 데이터 디스커버리 : 대화형으로 데이터를 시각화하여 가치있는 정보를 찾으려고 하는 프로세스
빅데이터 시대의 데이터 분석 기반
빅데이터의 기술
데이터 파이프라인 : 데이터 수집에서 워크플로 관리까지
- 일반적으로 차례대로 전달해나가는 데이터로 구성된 시스템을 '데이터 파이프라인'이라고 한다.
데이터 수집 : 벌크형과 스트리밍형의 데이터 전송
데이터 파이프라인은 데이터를 모으는 부분부터 시작한다. 데이터 전송의 방법은 크게 두가지

벌크형(bulk)
- 어디엔가 존재하는 데이터를 정리해서 추출하는 방법. 데이터베이스, 파일 서버 등에서 정기적으로 데이터를 수집하는 데 사용
스트리밍형(streaming)
- 차례대로 끊임없이 계속해서 보내는 방법. 모바일 애플리케이션과 임베디드 장비 등에서 널리 데이터를 수집하는데 사용
스트림처리와 배치처리
- 수정중