
빅데이터 처리 프로세스


HDFS 구조

HIVE, PIG
- MAPREDUCE는 자바 기반 병렬처리 프레임워크
- MAP REDUCE를 가지고 만든 언어 PIG (인터프리터 방식)
- SQL로 만든 언어 HIVE, 내부는 MAP REDUCE로 동작
- 결국 HIVE, PIG는 컴파일 되면서 아랫단에서 JAVA로 동작하는데, 개발자는 편할지 몰라도 시스템 자체에는 좋지 않을 수 있음
HADOOP ECOSYSTEM
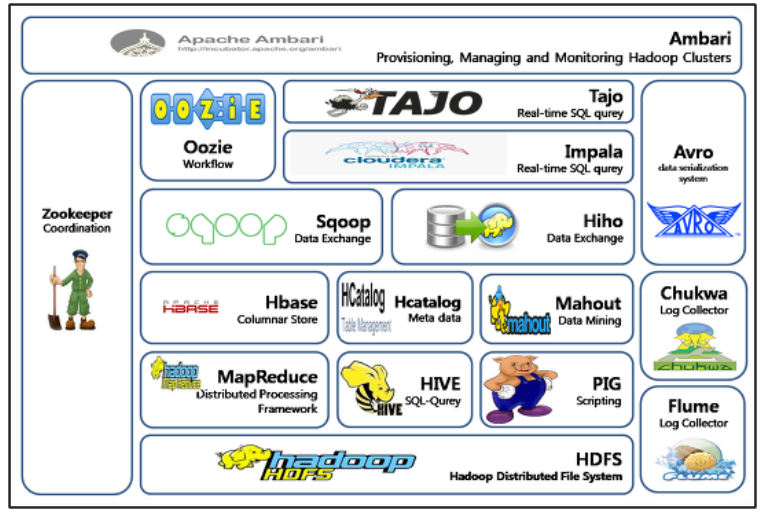
- 예전에는 하둡 버전에 맞춰서, 다른 프레임워크의 각각의 버전을 맞췄어야함
- 사람들이 불평불만을 하기 시작했는데, 다 같이 공생해야하니까 얘네들이 하나의 큰 단체를 만듬
- 하둡을 중심으로 큰 단체를 만들었다. 그래서 지금 버전이 업그레이드 되면,
- 공식 문서에 어떤 버전이 맞는지 업데이트 되면 공지함
- MAHOUT : 머신러닝 전용이였는데, 요즘 잘 안씀
- HBASE : 컬럼기반 DB 모델인데, 하둡이 만든 애들이 만들어서 하둡이랑 가장 호환이 잘됐음
- 반면 MONGODB는 하둡이랑 잘 연동시키지 않고(하둡 에코시스템 아님), 요즘 MONGODB가 그리드FS라는 분산파일시스템을 밀고 있음
HADOOP & SPARK & NOSQL

SPARK
- 고속 메모리 처리
- 머신러닝(TENSOR, TORCH에 비해 기능 작고 간단)
- SQL(사람들이 SQL을 선호해서, SQL 형태로 솔루션에 데이터를 넣었다 뺐다 할 수 있도록 제공)
- 시각화
- 프로그래밍 언어 지원(SCALA, PYTHON)
- 메모리를 지원하기 위한 기술 : STORM
참고
- 프로세서 : CPU
- 프로세스 : 실행 중인 프로그램(프로세서를 사용할 수 있는 권한을 할당받은)
- 프로세스가 실행되면 메모리에 데이터가 올라와야하는데, 프로세스들이 메모리에 계속 요청을 하는데, 이 과정에서 일부 프로세스를 메모리에서 내려야한다. 이 때 고려하는건, 사용시간과 사용횟수를 고려해서 메모리를 내린다.
- 메모리에서 내린다는게, 메모리에서 지우고 끝나는게 아니라 데이터가 변경해야하는데, 올렸다 내렸다를 반복하면 디스크 I/O가 계속 발생하는데 운영체제가 한번 올렸을 때 많이 사용하면서, 적게 왔다갔다 할까를 스케쥴링해준다. OS(LRU 알고리즘, LFU 알고리즘과 관련)
'데이터 노하우 > 꿀팁' 카테고리의 다른 글
| Airflow 관련 문의 기록 (0) | 2023.07.12 |
|---|---|
| Pandas 데이터 처리 효율성 전략(Pycon Korea) (2) | 2023.02.21 |
| Scaling 꿀팁 + 과적합 쉬운 비교 방법 (0) | 2023.02.10 |