
이 글은 PyCon Korea의 "뚱뚱하고 굼뜬(Pandas)를 위한 효과적인 다이어트 전략 - 오성우" 영상을 참고했습니다.
https://www.youtube.com/watch?v=0Vm9Yi_ig58
1. Memory Optimization
1-1 코드화
문자열로 된 데이터를 숫자/영어로 변환하여 데이터 크기 축소
- 남자 -> 0
- 여자 -> 1
- 서울특별시 -> 11
- 대구광역시 -> 45
- 정상 -> 0
- 비정상 -> 1
한글 문자열로된 범주 값을 숫자 형태로 변환하는 코드화 작업을 진행했더니 4.49GB -> 1.79GB로 크게 감소
1-2 데이터 형식 변환
데이터 형식에 따라서 표현하는 값의 범위와 사용하는 메모리 크기가 달라집니다.
컬럼마다 고정된 크기(Fixed-length)로 할당하기 때문에 크기가 작은 데이터 형식을 사용하면 메모리 사용량을 크게 줄일 수 있습니다.
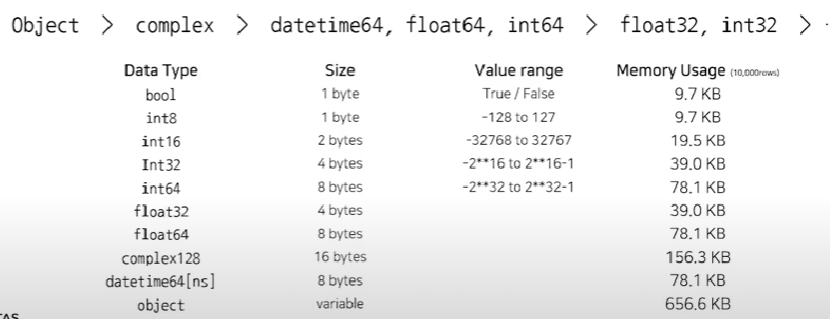
- 데이터 형식을 변환하는 방법
# 1. 데이터 형식을 아는 경우
# 컬럼의 타입을 지정해줘서, 메모리 사용량을 줄인다
data_types = {'col1' : 'int8', 'col2' : 'float32'}
df = pd.read_csv(data_path, dtype = data_types)
# 2\. 데이터를 불러왔지만 크기를 줄이고 싶은 경우
df = pd.read\_csv(data\_path)
data\_types = check\_dtypes(df)
df = df.astype(data\_types)
# 3\. 데이터가 커서 불러오지도 못하는 경우
# 첫번째 행만 갖고와서 컬럼값의 값들을 확인한다
# 이후 check\_dtypes 함수 구현해서 컬럼간 최대 메모리에 맞게 컬럼 타입 지정
columns = pd.read\_csv(data\_path, rows = 0).columns
data\_types = {col : check\_dtypes(df\[col\]) for col in columns}
df = pd.read\_csv(data\_path, dtype = data\_type)1-3 카테고리 데이터 형식 사용
- 특징
- Finite Value에 적합한 DataType으로 Unique Value가 반복해서 나타나는 경우 사용
- Int8로 데이터를 저장하고, Ordered와 Unordered 방식 모두 사용 가능
- 장점
- object를 Catgory로 변환했을 때 메모리 사용량 크게 감소
- 데이터 처리 및 분석속도 향상
- 시각화 등에서 편의성 향상
- 한계
- 범주가 무수히 많을 경우, object보다 비효율적
- 테스트
- object 타입에 대한 value_counts 시 2.3초 소요
- category 타입에 대한 value_counts 시 0.3초 소요
- 범주형 변수가 많은 경우, 기존 1722MB 사용 데이터가, 277MB까지 줄어드는 모습을 보인다
1-4 파일 저장 포맷 변경
- 일반적인 CSV 포맷의 단점
- string 기반으로 IO 효율이 떨어짐
- Meta data가 없어 각 컬럼의 데이터 형식 등에 대해 연속성을 가지고 사용불가
- 최근 많이 사용되고 있는 hdf5, parquet 포맷과 pickle, feather 같은 다른 포맷과 비교

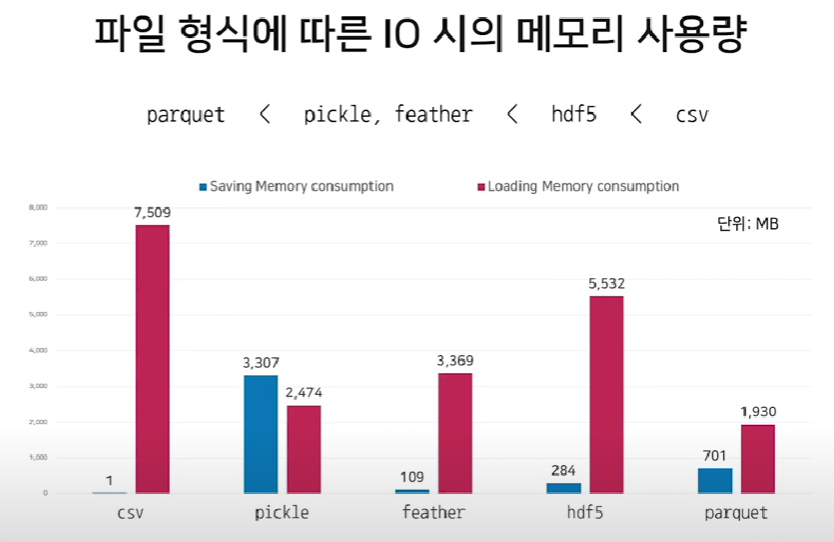
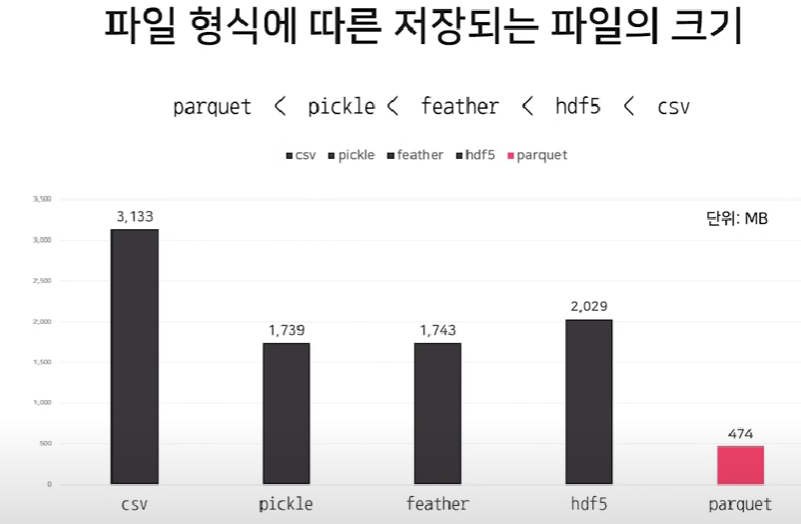
- 추천하는 파일 포맷 형식
- 개인사용목적 : feather, pickle
- 프로젝트, 협업목적 : parquet, hdf5
- parquet 사용시 장점
- Spark, Hive, Impala, AWS services, BigQuery와의 연계가 용이
- Pyspark, DAsk와 같은 프레임워크와 함께 사용할 때 편리
- AWS의 S3, AThena에 parquet 데이터를 바로 저장하거나 불러오기도함
- Hdf5 사용시 장점
- Pandas에서 저장한 hdf포맷 그대로 h5py 라이브러리로 사용가능
- 기타 Hadoop service와도 잘 맞음
2. Enhancing Performance
2-1 Vectorization
벡터화 연산을 사용하면 명시적으로 반복문을 사용하지 않고도 배열의 모든 원소에 대해 반복 연산이 가능합니다.

- 꿀팁(np.vectorize)
custom 함수의 vectorization을 쉽게 도와주는 np.vectorize
# 데코레이터로 @np.vectorize를 써주고, a와 b에 리스트를 넣으면 알아서 벡터연산을 해줌
@np.vectorize
def func(a,b):
return a * b2-2 Considering Efficient Algorithm
방법비교 / 상위 5개의 데이터를 불러오는 방법
- df[col].sort_values(ascending = False).head(5) / 7.8초 소요(예시 데이터)
- df[col].nlargest(5) / 0.68초 소요
상위 자료를 뽑을 땐 nlargest 쓰자
2-3 pandas apply???
데이터의 형태와 조건에 따라 아래에서부터 쓰는 것으로..

3. Adoption conventions
- Method chaning을 쓰는 걸 판다스 개발자들이 성능이 좋다고 말함. 오히려 추천하는 방법
3-1 inplae parameter
내부 알고리즘 상 inplace 실행 이후에도 메모리에 데이터가 남아있는 문제가 있다. 그냥 다시 변수에 재할당하는걸 판다스 개발자들은 말함

4. 판다스가 적절한 데이터 크기는?
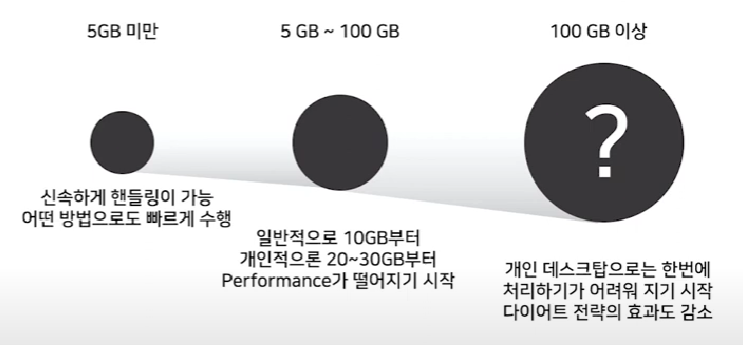
그렇다면 어떻게 처리할까
- 다른 데이터프레임 프레임워크
- dask, Modin
- GPU
- Numba, cuDF
- Parallelization module
- multiprocessing
- DBMS, Spark
'데이터 노하우 > 꿀팁' 카테고리의 다른 글
| Airflow 관련 문의 기록 (0) | 2023.07.12 |
|---|---|
| 빅데이터 처리 프로세스 (0) | 2023.04.04 |
| Scaling 꿀팁 + 과적합 쉬운 비교 방법 (0) | 2023.02.10 |