
PIG
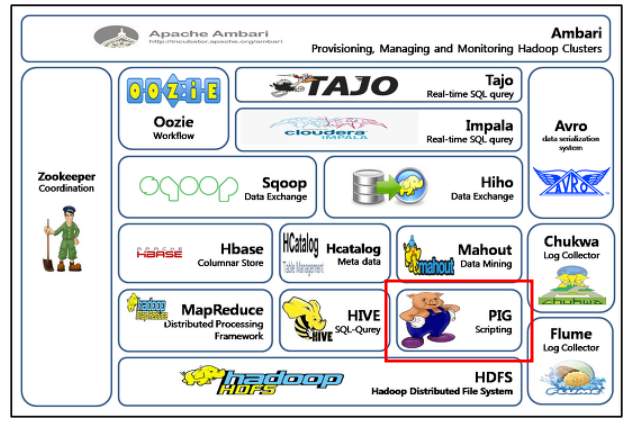
Pig는 대규모 데이터 처리를 위한 분산형 쿼리 언어 및 실행 환경입니다. Pig는 Hadoop에서 실행되며, Hadoop 클러스터 내에서 대규모 데이터 집합을 처리하는 데 사용됩니다.
Pig는 구조화되지 않은 데이터를 처리하는 데 적합한 언어로, 데이터를 표현하는 방식이 일반적인 행-열 구조가 아니더라도 데이터를 처리할 수 있습니다. Pig는 SQL과 유사한 구문을 제공하며, 사용자는 SQL과 유사한 방식으로 데이터를 처리할 수 있습니다.
Pig는 다양한 데이터 소스 (예 : HDFS, HBase, Amazon S3 등)에서 데이터를 읽어들이고, 이를 다양한 대상 (예 : HDFS, HBase, Relational Databases 등)으로 쓸 수 있습니다. Pig는 스크립트로 작성되며, 이를 Pig Latin이라는 언어로 작성합니다. Pig Latin은 대부분의 프로그래밍 언어에서 사용되는 제어 구문 (예 : if, for, while 등)과 함수를 지원합니다.
Pig는 Hadoop 클러스터에서 실행되며, 데이터 처리를 위해 MapReduce를 사용합니다. Pig는 MapReduce 작업을 자동으로 생성하므로 사용자는 MapReduce 프로그래밍에 대한 지식이 없어도 Pig를 사용하여 대규모 데이터를 처리할 수 있습니다. Pig는 대규모 데이터 처리를 단순화하고 생산성을 높이는 데 효과적입니다. Pig와 유사한 프레임워크로는, Hive, Presto가 있습니다. 하지만 다 각각의 쓰임새가 다릅니다.
PIG vs Hive vs Presto
Pig, Hive, Presto는 모두 대규모 데이터 처리를 위한 분산형 쿼리 프레임워크이지만, 각각의 특징과 사용 시나리오가 다릅니다.
Pig:
- Pig는 구조화되지 않은 데이터를 처리하는 데 적합한 분산형 쿼리 언어입니다.
- Pig는 스크립트 기반으로 작성되며, Pig Latin이라는 언어를 사용합니다.
- Pig는 데이터 처리를 위해 MapReduce를 사용하며, 사용자는 MapReduce 프로그래밍에 대한 지식이 없어도 Pig를 사용하여 대규모 데이터를 처리할 수 있습니다.
- Pig는 다양한 데이터 소스에서 데이터를 읽어들이고, 이를 다양한 대상으로 쓸 수 있습니다.
Hive:
- Hive는 구조화된 데이터를 처리하는 데 적합한 분산형 데이터 웨어하우징 시스템입니다.
- Hive는 SQL과 유사한 구문을 사용하며, 데이터 처리를 위해 MapReduce를 사용합니다.
- Hive는 테이블 생성, 스키마 정의, 데이터 쿼리 및 분석을 위한 다양한 함수를 제공합니다.
- Hive는 대용량의 정형 데이터를 처리하기에 적합합니다.
Presto:
- Presto는 대용량 분산 데이터 처리를 위한 고성능 SQL 쿼리 엔진입니다.
- Presto는 SQL과 유사한 구문을 사용하며, 데이터 처리를 위해 MapReduce를 사용하지 않습니다.
- Presto는 다양한 데이터 소스에서 데이터를 읽어들이고, 이를 다양한 대상으로 쓸 수 있습니다.
- Presto는 높은 처리 속도와 대화형 데이터 분석을 지원하며, 대용량 비정형 데이터 처리에 적합합니다.
따라서, Pig는 구조화되지 않은 데이터 처리, Hive는 정형 데이터 처리 및 분석, Presto는 대용량 비정형 데이터 처리에 적합합니다.
PIG 기초 명령어
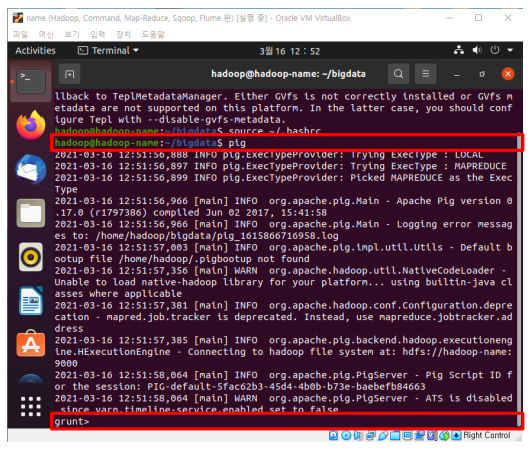
(1) pig를 실행합니다.
pig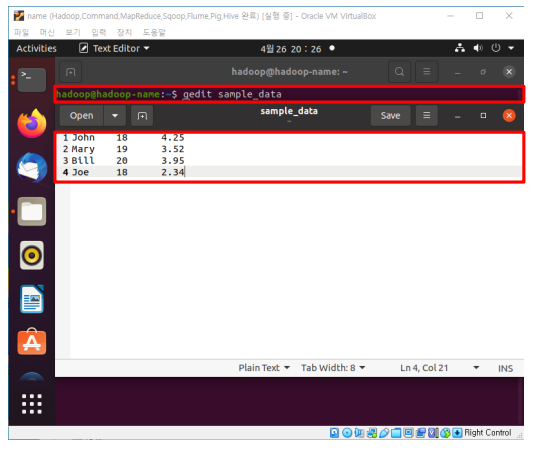
(2) sample_data를 생성합니다. 우분투에선 gedit, 레드햇에선 vi 명령어를 사용합니다. 위처럼 데이터를 생성합니다.
gedit sample_data
vi sample_data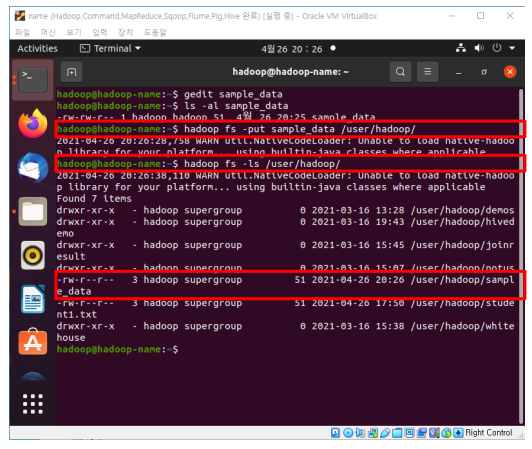
(3) 예제 데이터를 하둡 파일시스템에 넣습니다.
hadoop fs –put sample_data /user/hadoop
hadoop fs –ls /user/hadoop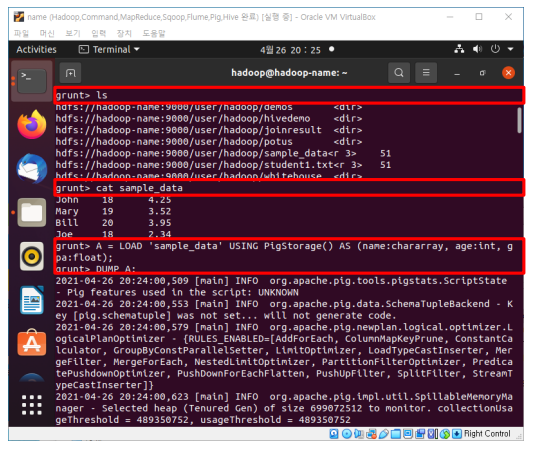
(4) 생성한 sample_data를 불러와서 각 속성의 이름과 데이터 타입을 정하고, 출력합니다.
ls
cat sample_data
A = LOAD 'sample_data' USING PigStorage() AS (name:chararray, age:int, gpa:float);
DUMP A;
https://pig.apache.org/docs/latest/index.html
Overview
Overview The Pig Documentation provides the information you need to get started using Pig. If you haven't already, download Pig now: . Begin with the Getting Started guide which shows you how to set up Pig and how to form simple Pig Latin statements. When
pig.apache.org
이 외 명령어는 해당 문서를 참고하면 됩니다. 감사합니다:)
'데이터 엔지니어링 > 하둡 에코 시스템' 카테고리의 다른 글
| [MongoDB]pymongo로 간단한 프로그램 만들기 (3) | 2023.05.18 |
|---|---|
| [MONGODB] 몽고DB 로컬에 설치하고 파이썬 연동하기 (0) | 2023.05.18 |
| [HIVE] 기본 개념 및 실습 (0) | 2023.05.16 |
| [Flume] 기본 개념 및 설치 (0) | 2023.05.10 |