
안녕하세요. 오늘은 DOCKER를 활용해서 딥러닝 모델이 포함된 이미지를 만들고, 이미지를 통해서 AWS LAMBDA로 매번 호출해보겠습니다. 이번에 프로젝트에서 사용되는 로직은 다음과 같습니다.
- DB에 있는 리뷰 데이터(restaurant_review 테이블) 호출
- 리뷰 데이터를 자연어 처리를 통해서 긍/부정 이진 분류
- 긍정 값으로 분류된 확률 값(0 ~ 1 사이)을 새로운 컬럼으로 생성
- restaurant_id를 기준으로 긍정 확률 평균값 생성
- 해당 평균 값에 5를 곱해서, 5점 만점의 리뷰 포인트
- 집계된 데이터를 restaurant 테이블의 star_rating 컬럼에 업데이트
- 하루에 한번씩 실행
이런 로직을 고민하고 만든 이유는, 최근 많은 사이트에서, 별점에 대한 신뢰성이 떨어진다는 여론과 이걸 해결할 방법을 고민하다가, 리뷰 기반의 블랙박스 시스템을 만들어보고자 이렇게 구현하기로 하였습니다.

1. DOCKER IMAGE 생성
AWS LAMBDA는 ZIP 파일 업로드 방식으로, 패키지를 올렸을 때 제한 용량이 250MB입니다. 이번 프로젝트의 경우는 TENSORFLOW를 사용해서 TF만 1GB가 넘어가기 때문에, 도커로 이미지를 생성하는 방식을 사용하였습니다.
먼저 한국어 자연어 처리에 가장 많이 사용되는 KONLPY가 JVM을 활용하기 때문에, 도커 이미지 생성에 자바까지 설치를 해줬어야했습니다. 따라서 아마존에서 제공하는 아마존-리눅스 파이썬 3.10 base_image 위에, 자바를 설치했습니다.
또 모델 용량이 그렇게 크지 않기 때문에, git 레퍼지토리의 파일을 다운로드 받아서, 모델과 토크나이저를 받고, 코드까지 실행시키는 방식으로 이미지를 만들었습니다.
# aws 제공 lambda base python image
FROM public.ecr.aws/lambda/python:3.10
ENV LANG=C.UTF-8
ENV DEBIAN_FRONTEND=noninteractive
RUN yum update -y && \
yum install -y tzdata g++ curl
# install java
RUN curl -L -O https://corretto.aws/downloads/latest/amazon-corretto-8-x64-linux-jdk.rpm && \
yum install -y ./amazon-corretto-8-x64-linux-jdk.rpm && \
rm -f ./amazon-corretto-8-x64-linux-jdk.rpm
ENV JAVA_HOME="/usr/lib/jvm/java-1.8.0-amazon-corretto"
# copy resources
COPY . .
# pip update
RUN /var/lang/bin/python3.10 -m pip install --upgrade pip
# install git
RUN yum install git -y
# 미리 구성된 github clone
RUN git clone https://<개인 깃 액세스 토큰>@github.com/sangwookWoo/nlp_lambda
# install packages
RUN pip install -r nlp_lambda/requirements.txt
# /var/task/ 경로로 실행파일 복사
RUN cp nlp_lambda/rating_update.py /var/task/
RUN cp -r nlp_lambda/models /var/task/
RUN cp -r nlp_lambda/plugins /var/task/
# 실행 시 lambda_function.py의 lambda_handler 함수를 실행시킴을 정의
CMD ["rating_update.lambda_handler"]이렇게 정의된 Dockerfile을 해당 명령어로 실행시켜서, 이미지를 만듭니다.
docker build -t nlp-lambda . --no-cache약 4.4GB 정도 됩니다. 이렇게 만든 이미지의 id를 가져와서(docker images), AMAZONE ECR 위에 올릴 겁니다. 먼저 ECR에 프라이빗 레포지토리를 생성해두면 되는데, 방법은 간단했습니다.
- AWS ECR 검색
- 레포지토리 클릭 후, 레포지토리 생성 클릭
- 레포지토리 이름 주고 바로 생성

저 모자이크 된 URL 부분을 복사해두셨다가, 이미지를 저 곳으로 넣으면 됩니다.
2. DOCKER 이미지 PUSH(AWS ECR)
aws configure(1) 먼저 로컬 환경에서 AWS 계정 인증을 받아야합니다. 해당 명령어로 계정을 등록합니다.
# ACCOUNT_ID 변수에 AWS 계정값 등록
export ACCOUNT_ID=$(aws sts get-caller-identity --output text --query Account)(2) ACCOUNT_ID 변수에 AWS 계정값을 등록합니다. 윈도우는 export를 set?으로 바꾸면 됐던 걸로 기억합니다!
docker tag <이미지ID> <복붙해둔URI>(3) docker image를 복붙해둔 url로 태깅합니다. URI 이름으로 이미지가 복사되어 있습니다.
aws ecr get-login-password --region ap-northeast-2 | docker login --username AWS --password-stdin <복붙해둔URI>(4) 이렇게 입력해서, AWS ECR에 로그인합니다.
docker push <복붙해둔URI>(5) ECR의 레포지토리로, 이미지 파일을 PUSH 합니다.
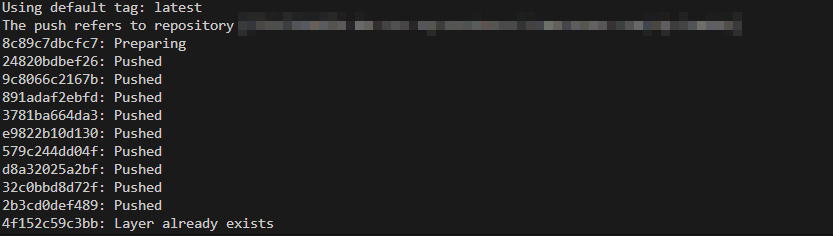
3. AWS LAMBDA
이제 해당 이미지로 LAMBDA 함수를 생성합니다.
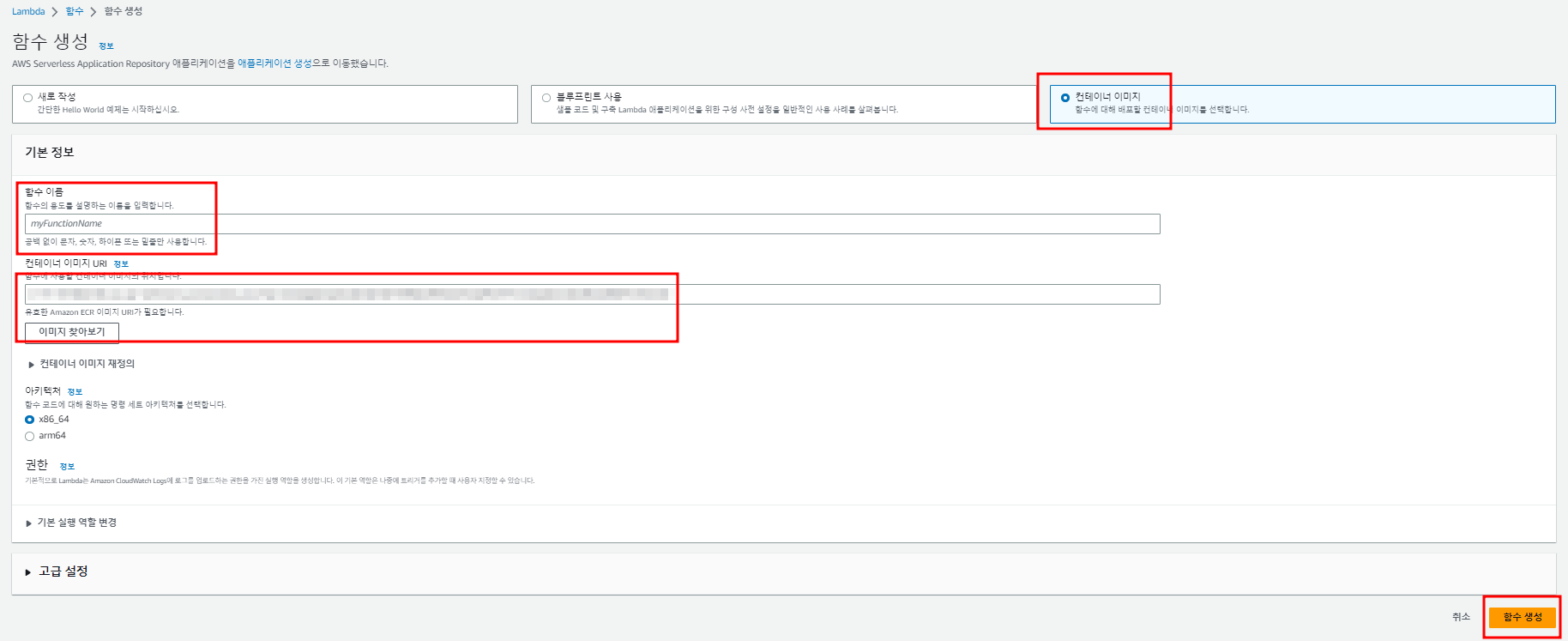
- 컨테이너 이미지로 생성하시면 되고, 함수의 이름을 설정합니다.
- ECR에 방금 업로드한 컨테이너 이미지를 가져온 후 함수를 생성합니다.
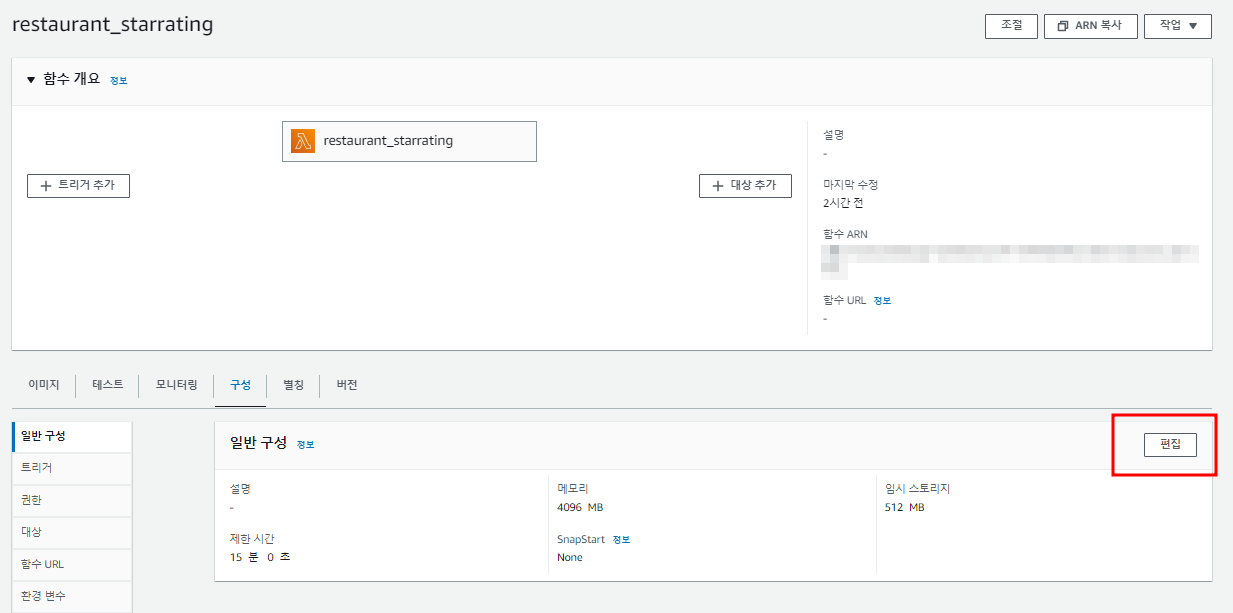
- 생성이 완료되면, 구성 메뉴에서 편집에 들어가 메모리와 제한시간 등을 설정합니다.
- 저의 경우엔 4096MB, 제한 시간은 15분으로 설정했습니다.

- 이후 테스트 탭에서, 테스트를 클릭해서 함수가 잘 작동되는지 테스트해봅니다.
- 잘 작동된다면, 해당 함수의 일정을 등록해보겠습니다.
4. 일정마다 실행

만들어진 AWS LAMBDA 함수에서, 트리거 추가를 클릭합니다.(제 경우는 이미 만들어놔서, TRIGGER가 있습니다!)
- 트리거는 EventBridge를 선택하고, 새 규칙을 생성합니다. 규칙 이름과 규칙 설명을 정합니다.
- 이 때 예약 표현식을 선택하고, 크론 표현식으로 작성합니다.
- 이 때 기준은 UTC 시간이므로, 한국 시간에서 9시간 뺀 시간으로 작성해줍니다(저는 00시 10분에 실행하려고 합니다)
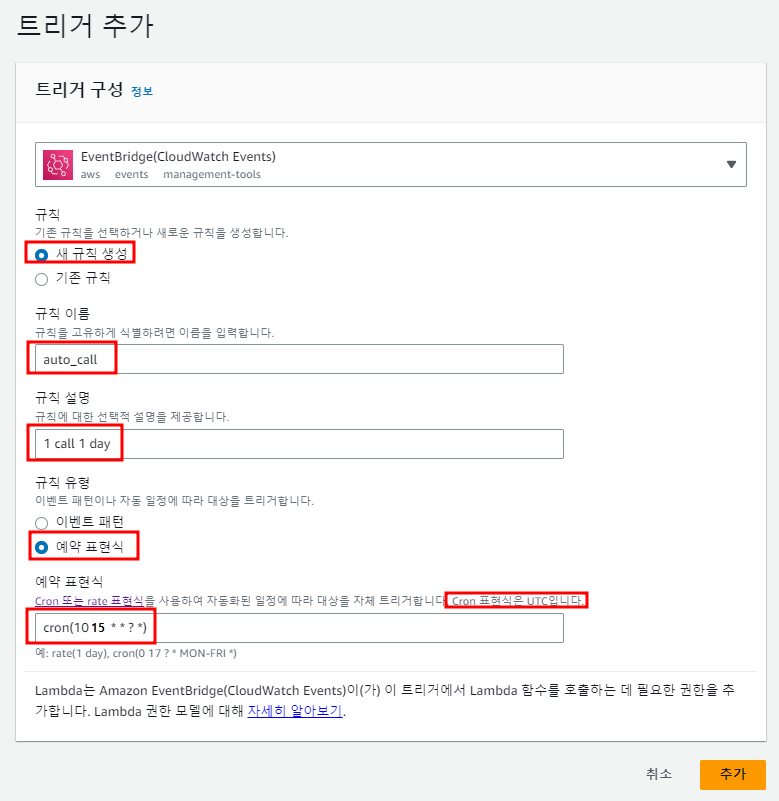
이렇게 해서 추가를 마쳐주시면, 아까 보신 것처럼

함수는 이런 구성이 됩니다. 이제 LAMBDA가 하루에 한번씩 리뷰를 집계해서 업데이트 합니다. 맨 아래에는 업데이트 관련 파이썬 코드 적어두겠습니다.
5. 파이썬 코드
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import load_model
from tqdm import tqdm
import pandas as pd
from konlpy.tag import Okt
import pickle
import re
from plugins import db_connector
import logging
import os
filePath, fileName = os.path.split(__file__)
def lambda_handler(event, context):
conn, cursor = db_connector.mysql()
try:
# START
print('############## Start To Update Review Star Rating')
# okt 정의
okt = Okt()
# tqdm(pandas)
tqdm.pandas()
# 불용어처리
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 토큰 불러오기
with open('./models/tokenizer.pickle', 'rb') as handle:
tokenizer = pickle.load(handle)
# 모델 불러오기
loaded_model = load_model('./models/best_model.h5')
# extact
df = extract_restaurant_review(cursor)
# transform
grouping = calculate_star_rating(df , okt, stopwords, tokenizer, loaded_model)
# load
load_mysql(grouping, cursor)
# log
print('############## Success To Update Restaruant Star Rating')
return 'Success'
except Exception as e:
print(e)
return 'Fail'
def extract_restaurant_review(cursor):
# db connect
review_cnt = cursor.execute('select restaurant_id, review from restaurant_review;')
if review_cnt == 0:
print('There is No Review')
raise
# extract data
df = pd.DataFrame(cursor.fetchall())
df = df.rename(columns={0: 'restaurant_id', 1: 'review'})
return df
'''Calculate Star Rating'''
def calculate_star_rating(df, okt, stopwords, tokenizer, loaded_model):
# processing
df['padding'] = df['review'].progress_apply(lambda x : processing(x, okt, stopwords, tokenizer))
# function_define
def data_generator():
for item in df['padding'].values:
yield item.flatten()
# predict
dataset = tf.data.Dataset.from_generator(data_generator, output_signature=tf.TensorSpec(shape=(None,), dtype=tf.int32))
batched_data = dataset.batch(64)
predictions = loaded_model.predict(batched_data)
df['prediction'] = predictions
# star_rating calculate
# 기준 : restaurant_id , prediction 평균값 구한 후, 평균 값 구해서 * 5
grouping = df.groupby('restaurant_id')['prediction'].mean() * 5
grouping = grouping.reset_index()
return grouping
def processing(new_sentence, okt, stopwords, tokenizer):
# 패딩 길이 정의
max_len = 30
new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence)
new_sentence = okt.morphs(new_sentence, stem=True) # 토큰화
new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거
encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩
return pad_new
'''Calculate Star Rating end'''
def load_mysql(grouping, cursor):
# Update
cursor.execute('BEGIN;')
try:
for idx in grouping.index:
restaurant_id = grouping.loc[idx, 'restaurant_id']
star_rating = grouping.loc[idx, 'prediction']
sql = f"UPDATE restaurant SET star_rating = {star_rating} WHERE id = {restaurant_id};"
print(sql)
cursor.execute(sql)
cursor.execute('COMMIT;')
except Exception as e:
cursor.execute('ROLLBACK;')
print(e)
raise
6. 참고자료
https://hub.docker.com/r/theeluwin/ubuntu-konlpy/dockerfile
Docker
hub.docker.com
https://docs.docker.com/engine/reference/commandline/build/
docker build
docker build: The `docker build` command builds Docker images from a Dockerfile and a "context". A build's context is the set of files located in the specified `PATH` or `URL`....
docs.docker.com
'AWS' 카테고리의 다른 글
| Redis, AWS ElasticCache 정리 (2) | 2023.07.13 |
|---|---|
| [AWS REDSHIFT] AIRFLOW S3 → Redshift UPSERT 관련 에러('syntax error at or near "#"') (0) | 2023.06.17 |
| [S3] 버킷 생성 및 boto3 파일 업로드, 파일 읽기 실습 (0) | 2023.05.14 |
| [S3] AMZON S3 기초개념 (2) | 2023.05.14 |
| [EC2]AWS EC2 MOBAXTERM 연결 (0) | 2023.04.16 |