
먼저 이 글은 저와 같이 REDSHIFT를 AIRFLOW와 연동해서 쓸 때 생기는 문제에 관한 글입니다. 문서가 너무 없고, 저만 겪는 상황 같아서, 열심히 삽질한 결과 작성해놓습니다. 이 글을 읽어보실 분들의 조건은 다음과 같습니다.
1. 에러 상황
(1) Redshift Cluster 사용
(2) Delimited identifiers를 사용하지 않으면, Syntax Error가 발생하는가?
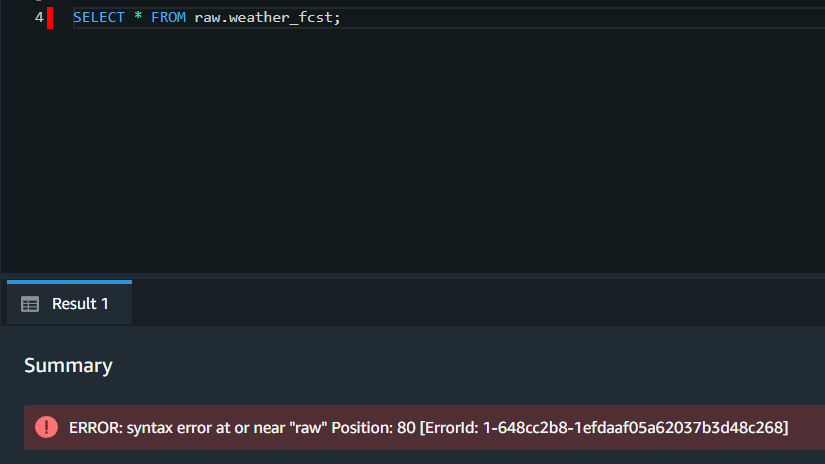
(3) Airflow S3ToRedshiftOperator를 사용해서, UPSERT 방식으로 데이터를 redshift에 로드하려고 하는가?
(4) Schema, Table 명을 Delimited identifiers를 사용해서 구성했는가?
여기까지 오셨으면 저랑 같은 상황입니다.. 일단 웹에 관련 정보는 없어서 혼자서 해결한 방법 공유드립니다.
2. S3ToRedshiftOperator
s3_to_redshift = S3ToRedshiftOperator(
task_id = f's3_to_redshift_{table}',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = '"' + schema + '"',
table = '"' + table + '"',
copy_options=['csv'],
method = 'UPSERT',
upsert_keys = ["id", "created_date"],
redshift_conn_id = "redshift_dev_db",
dag = dag
)일단 Delimited identifiers(구분 식별자) 사용을 위해서 schema와 table 명에 "를 양쪽에 추가해줬습니다. 이렇게만 해도 REPLACE 메소드는 무리 없이 잘 됐습니다. 그런데 Upsert 메소드를 사용하면 이런 에러가 발생했습니다.
{'S': 'ERROR', 'C': '42601', 'M': 'syntax error at or near "#"', 'P': '14', 'F': '/home/ec2-user/padb/src/pg/src/backend/parser/parser_scan.l', 'L': '732', 'R': 'yyerror'}
일단 sql 에러인 걸로 확인 했고, # 관련 에러는 aws redshift의 임시테이블 관련 오류입니다. 관련 문서입니다.
https://docs.aws.amazon.com/redshift/latest/dg/r_CREATE_TABLE_AS.html
CREATE TABLE AS - Amazon Redshift
If you specify a table name that begins with '# ', the table is created as a temporary table. For example: create table #newtable (id) as select * from oldtable;
docs.aws.amazon.com

여기서 삽질을 꽤나 했는데, 결국엔 Upsert 관련 로직을 생각해보면 되는 문제였습니다. 아마도 S3ToRedshiftOperator가 임시테이블을 사용한 upsert 로직을 사용하는 걸로 보입니다. airflow 공식문서를 확인해보겠습니다.
airflow.providers.amazon.aws.transfers.s3_to_redshift — apache-airflow-providers-amazon Documentation
airflow.apache.org
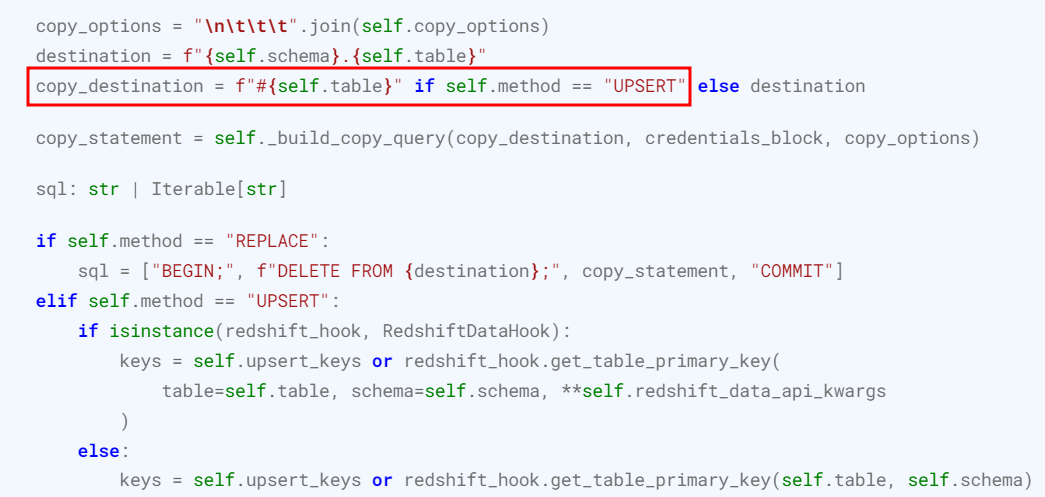
확인해보니, 해당 오퍼레이터는 method가 'UPSERT'인 경우엔 copy_destination을 잡고 기존 테이블에 #만 붙여서 임시테이블로 만들고 있었습니다. 그러면, 제가 파라미터로 준 쌍따옴표 붙은 파라미터 명이 그대로 들어오겠군뇨....
제 hotplaces 테이블은, #"hotplaces” 이런 테이블명이 되면서 오류를 만들었습니다. 실제로는 "#hotplaces"가 되어야, 임시테이블을 성공적으로 만들고 copy가 될 것 같습니다.
3. 문제 해결
내부 코드를 찾아서 들어가줍니다. S3ToRedshiftOperator 함수를 사용한 곳이 있다면, 거기서 타고 들어가도 되고, 저는 vs코드 권한 문제로 에어플로우 내부 코드를 건들 수 없어서, 터미널에서 vi로 편집했습니다.
경로 예시입니다.
- /usr/local/lib/python3.10/dist-packages/airflow/providers/amazon/aws/transfers/s3_to_redshift.py
# 추가 및 수정
copy_table = self.table.replace('"', '')
copy_destination = f'"#{copy_table}"' if self.method == "UPSERT" else destination이 코드를 중간에 넣어주면 됩니다. 이렇게 되면 Delimited identifiers(쌍따옴표)를 제자리로 가져다 놓고, 해당 # 에러가 발생하지 않습니다. excute 부분 전체 코드입니다.
def execute(self, context: Context) -> None:
redshift_hook = RedshiftSQLHook(redshift_conn_id=self.redshift_conn_id)
conn = S3Hook.get_connection(conn_id=self.aws_conn_id)
if conn.extra_dejson.get("role_arn", False):
credentials_block = f"aws_iam_role={conn.extra_dejson['role_arn']}"
else:
s3_hook = S3Hook(aws_conn_id=self.aws_conn_id, verify=self.verify)
credentials = s3_hook.get_credentials()
credentials_block = build_credentials_block(credentials)
copy_options = "\n\t\t\t".join(self.copy_options)
destination = f"{self.schema}.{self.table}"
# 추가 및 수정
copy_table = self.table.replace('"', '')
copy_destination = f'"#{copy_table}"' if self.method == "UPSERT" else destination
#copy_destination = f"#{self.table}" if self.method == "UPSERT" else destination
#수정 끝
copy_statement = self._build_copy_query(copy_destination, credentials_block, copy_options)
sql: str | Iterable[str]
if self.method == "REPLACE":
sql = ["BEGIN;", f"DELETE FROM {destination};", copy_statement, "COMMIT"]
elif self.method == "UPSERT":
keys = self.upsert_keys or redshift_hook.get_table_primary_key(self.table, self.schema)
if not keys:
raise AirflowException(
f"No primary key on {self.schema}.{self.table}. Please provide keys on 'upsert_keys'"
)
where_statement = " AND ".join([f"{self.table}.{k} = {copy_destination}.{k}" for k in keys])
sql = [
f"CREATE TABLE {copy_destination} (LIKE {destination});",
copy_statement,
"BEGIN;",
f"DELETE FROM {destination} USING {copy_destination} WHERE {where_statement};",
f"INSERT INTO {destination} SELECT * FROM {copy_destination};",
"COMMIT",
]
else:
sql = copy_statement
self.log.info("Executing COPY command...")
redshift_hook.run(sql, autocommit=self.autocommit)
self.log.info("COPY command complete...")
4. 근본적인 문제는..?
Delimited identifiers를 사용하지 않는 상태라면, 애초에 문제가 없을 것 같습니다. 그래서 파라미터 옵션도 찾아봐도 나오는게 없어서, 결국 급한대로 이렇게 해결했습니다,, 혹시라도 이 부분에 대해서 아시는 분이나, 질문 있으신 분들은 댓글 남겨주시면 감사하겠습니다ㅜㅜ 시간이 나는대로 관련 방법 찾아보고 다시 포스팅을 하던지, 댓글로 남겨놓겠습니다! 감사합니다.
- 8월 1일 문제 발견
테이블명을 "raw"로 사용했기 때문에 반드시 구분 식별자를 사용했어야했음 <- redshift의 예약어였기 때문에, 반드시 구분 식별자를 써줘야했던 것............................
https://docs.aws.amazon.com/ko_kr/redshift/latest/dg/r_pg_keywords.html
예약어 - Amazon Redshift
START 및 CONNECT는 예약어가 아니지만, 쿼리에서 START 및 CONNECT를 테이블 별칭으로 사용하는 경우에는 런타임 시 오류가 발생하지 않도록 구분된 식별자 또는 AS를 사용하세요.
docs.aws.amazon.com
'AWS' 카테고리의 다른 글
| Redis, AWS ElasticCache 정리 (2) | 2023.07.13 |
|---|---|
| [AWS LAMBDA] DOCKER 활용 AWS LAMBDA 딥러닝 모델 적용 (1) | 2023.06.11 |
| [S3] 버킷 생성 및 boto3 파일 업로드, 파일 읽기 실습 (0) | 2023.05.14 |
| [S3] AMZON S3 기초개념 (2) | 2023.05.14 |
| [EC2]AWS EC2 MOBAXTERM 연결 (0) | 2023.04.16 |
먼저 이 글은 저와 같이 REDSHIFT를 AIRFLOW와 연동해서 쓸 때 생기는 문제에 관한 글입니다. 문서가 너무 없고, 저만 겪는 상황 같아서, 열심히 삽질한 결과 작성해놓습니다. 이 글을 읽어보실 분들의 조건은 다음과 같습니다.
1. 에러 상황
(1) Redshift Cluster 사용
(2) Delimited identifiers를 사용하지 않으면, Syntax Error가 발생하는가?
(3) Airflow S3ToRedshiftOperator를 사용해서, UPSERT 방식으로 데이터를 redshift에 로드하려고 하는가?
(4) Schema, Table 명을 Delimited identifiers를 사용해서 구성했는가?
여기까지 오셨으면 저랑 같은 상황입니다.. 일단 웹에 관련 정보는 없어서 혼자서 해결한 방법 공유드립니다.
2. S3ToRedshiftOperator
s3_to_redshift = S3ToRedshiftOperator(
task_id = f's3_to_redshift_{table}',
s3_bucket = s3_bucket,
s3_key = s3_key,
schema = '"' + schema + '"',
table = '"' + table + '"',
copy_options=['csv'],
method = 'UPSERT',
upsert_keys = ["id", "created_date"],
redshift_conn_id = "redshift_dev_db",
dag = dag
)일단 Delimited identifiers(구분 식별자) 사용을 위해서 schema와 table 명에 "를 양쪽에 추가해줬습니다. 이렇게만 해도 REPLACE 메소드는 무리 없이 잘 됐습니다. 그런데 Upsert 메소드를 사용하면 이런 에러가 발생했습니다.
{'S': 'ERROR', 'C': '42601', 'M': 'syntax error at or near "#"', 'P': '14', 'F': '/home/ec2-user/padb/src/pg/src/backend/parser/parser_scan.l', 'L': '732', 'R': 'yyerror'}
일단 sql 에러인 걸로 확인 했고, # 관련 에러는 aws redshift의 임시테이블 관련 오류입니다. 관련 문서입니다.
https://docs.aws.amazon.com/redshift/latest/dg/r_CREATE_TABLE_AS.html
CREATE TABLE AS - Amazon Redshift
If you specify a table name that begins with '# ', the table is created as a temporary table. For example: create table #newtable (id) as select * from oldtable;
docs.aws.amazon.com
여기서 삽질을 꽤나 했는데, 결국엔 Upsert 관련 로직을 생각해보면 되는 문제였습니다. 아마도 S3ToRedshiftOperator가 임시테이블을 사용한 upsert 로직을 사용하는 걸로 보입니다. airflow 공식문서를 확인해보겠습니다.
airflow.providers.amazon.aws.transfers.s3_to_redshift — apache-airflow-providers-amazon Documentation
airflow.apache.org
확인해보니, 해당 오퍼레이터는 method가 'UPSERT'인 경우엔 copy_destination을 잡고 기존 테이블에 #만 붙여서 임시테이블로 만들고 있었습니다. 그러면, 제가 파라미터로 준 쌍따옴표 붙은 파라미터 명이 그대로 들어오겠군뇨....
제 hotplaces 테이블은, #"hotplaces” 이런 테이블명이 되면서 오류를 만들었습니다. 실제로는 "#hotplaces"가 되어야, 임시테이블을 성공적으로 만들고 copy가 될 것 같습니다.
3. 문제 해결
내부 코드를 찾아서 들어가줍니다. S3ToRedshiftOperator 함수를 사용한 곳이 있다면, 거기서 타고 들어가도 되고, 저는 vs코드 권한 문제로 에어플로우 내부 코드를 건들 수 없어서, 터미널에서 vi로 편집했습니다.
경로 예시입니다.
- /usr/local/lib/python3.10/dist-packages/airflow/providers/amazon/aws/transfers/s3_to_redshift.py
# 추가 및 수정
copy_table = self.table.replace('"', '')
copy_destination = f'"#{copy_table}"' if self.method == "UPSERT" else destination이 코드를 중간에 넣어주면 됩니다. 이렇게 되면 Delimited identifiers(쌍따옴표)를 제자리로 가져다 놓고, 해당 # 에러가 발생하지 않습니다. excute 부분 전체 코드입니다.
def execute(self, context: Context) -> None:
redshift_hook = RedshiftSQLHook(redshift_conn_id=self.redshift_conn_id)
conn = S3Hook.get_connection(conn_id=self.aws_conn_id)
if conn.extra_dejson.get("role_arn", False):
credentials_block = f"aws_iam_role={conn.extra_dejson['role_arn']}"
else:
s3_hook = S3Hook(aws_conn_id=self.aws_conn_id, verify=self.verify)
credentials = s3_hook.get_credentials()
credentials_block = build_credentials_block(credentials)
copy_options = "\n\t\t\t".join(self.copy_options)
destination = f"{self.schema}.{self.table}"
# 추가 및 수정
copy_table = self.table.replace('"', '')
copy_destination = f'"#{copy_table}"' if self.method == "UPSERT" else destination
#copy_destination = f"#{self.table}" if self.method == "UPSERT" else destination
#수정 끝
copy_statement = self._build_copy_query(copy_destination, credentials_block, copy_options)
sql: str | Iterable[str]
if self.method == "REPLACE":
sql = ["BEGIN;", f"DELETE FROM {destination};", copy_statement, "COMMIT"]
elif self.method == "UPSERT":
keys = self.upsert_keys or redshift_hook.get_table_primary_key(self.table, self.schema)
if not keys:
raise AirflowException(
f"No primary key on {self.schema}.{self.table}. Please provide keys on 'upsert_keys'"
)
where_statement = " AND ".join([f"{self.table}.{k} = {copy_destination}.{k}" for k in keys])
sql = [
f"CREATE TABLE {copy_destination} (LIKE {destination});",
copy_statement,
"BEGIN;",
f"DELETE FROM {destination} USING {copy_destination} WHERE {where_statement};",
f"INSERT INTO {destination} SELECT * FROM {copy_destination};",
"COMMIT",
]
else:
sql = copy_statement
self.log.info("Executing COPY command...")
redshift_hook.run(sql, autocommit=self.autocommit)
self.log.info("COPY command complete...")
4. 근본적인 문제는..?
Delimited identifiers를 사용하지 않는 상태라면, 애초에 문제가 없을 것 같습니다. 그래서 파라미터 옵션도 찾아봐도 나오는게 없어서, 결국 급한대로 이렇게 해결했습니다,, 혹시라도 이 부분에 대해서 아시는 분이나, 질문 있으신 분들은 댓글 남겨주시면 감사하겠습니다ㅜㅜ 시간이 나는대로 관련 방법 찾아보고 다시 포스팅을 하던지, 댓글로 남겨놓겠습니다! 감사합니다.
- 8월 1일 문제 발견
테이블명을 "raw"로 사용했기 때문에 반드시 구분 식별자를 사용했어야했음 <- redshift의 예약어였기 때문에, 반드시 구분 식별자를 써줘야했던 것............................
https://docs.aws.amazon.com/ko_kr/redshift/latest/dg/r_pg_keywords.html
예약어 - Amazon Redshift
START 및 CONNECT는 예약어가 아니지만, 쿼리에서 START 및 CONNECT를 테이블 별칭으로 사용하는 경우에는 런타임 시 오류가 발생하지 않도록 구분된 식별자 또는 AS를 사용하세요.
docs.aws.amazon.com
'AWS' 카테고리의 다른 글
| Redis, AWS ElasticCache 정리 (2) | 2023.07.13 |
|---|---|
| [AWS LAMBDA] DOCKER 활용 AWS LAMBDA 딥러닝 모델 적용 (1) | 2023.06.11 |
| [S3] 버킷 생성 및 boto3 파일 업로드, 파일 읽기 실습 (0) | 2023.05.14 |
| [S3] AMZON S3 기초개념 (2) | 2023.05.14 |
| [EC2]AWS EC2 MOBAXTERM 연결 (0) | 2023.04.16 |