
Pandas(Panel Datas)
판다스는 주로 데이터 분석에 사용됩니다.
대부분의 데이터는 시계열(Series)이나 표(table)의 형태로 나타낼 수 있습니다.
Pandas 패키지는 이러한 데이터를 다루기 위한 Series 클래스와 DataFrame 클래스를 제공합니다.
숫자 테이블과 시계열을 조작하기 위한 데이터 구조와 연산을 제공합니다.
Pandas package import
import pandas as pdSeries class
Series 클래스는 Numpy에서 제공하는 1차원 배열과 그 모양이 비슷합니다.
하지만 Series data는 배열과 다르게 각 데이터의 의미를 표시하는 index를 붙일 수 있습니다.
데이터 자체는 값(value)라고 합니다.
series = pd.Series([10,20,30,40,50,60,70,80], index = [_ for _ in range(1,9)])
# object 객체는 최상위의 객체, 모든 걸 포괄할 수 있는 객체 Series 객체를 만들 때는 첫 인수로 data, 두 번째로는 index를 넣습니다.
data 값으로 iterable, 배열, scalar value, dict(key와 index를 동일하게 사용하거나 생략)를 사용할 수
있습니다.
index는 label이라고도 합니다. index는 data와 length가 동일해야합니다.
label은 꼭 유일(unique)할 필요는 없습니다. 다만 반드시 hashable type만 사용 가능합니다.
만약 index를 생략할 경우 Rangeindex(0, 1, ..., n)을 제공합니다.
# 긴 숫자의 경우 언더바를 숫자 사이사이에 넣어서, 3자리씩 끊어서 작성할 수 있다.
s = pd.Series([9_904_312, 3_448_737, 2_890_451, 2_466_052], index = ['서울', '부산', '인천', '대구'])
sseries 생성하기1
만약 index를 지정하지 않고 Series를 만들면 Series의 index는 0부터 시작하는 정수 값이 됩니다.
- Series의 index는 index 속성으로 접근 가능
- Series의 value는 1차원 배열(ndarray)/ values 속성으로 접근 가능
- name 속성을 이용하여 Series 데이터에 이름을 붙일 수 있습니다.
- index.name 속성으로 Series의 인덱스에도 이름을 붙일 수 있습니다.
s.index
s.values
s.name = "인구"
s.index.name = "도시"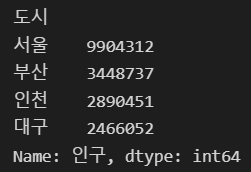
Series 생성하기2
- Series 객체를 만들 때 data에 dict를 사용해도 됩니다.
- data가 dict일 때 index가 최초에 dict의 key로 만들어집니다.
- 그 후 Series는 index 키워드로 전달 받은 인수로 index를 재할당합니다.
- 그래서 밑의 예제와 같이 Series 객체 값이 NaN 결과를 출력하는 것을 볼 수 있습니다.
dict = {'a' : 1, 'b' : 2, 'c' : 3}
ser = pd.Series(data = dict, index = ['x','y','z'])
ser
# NaN 값이 float 자료형에서만 표현 가능하므로 결과가 float 자료형이 되었다는 점에 주의
- index 지정 없이 dict 객체만 가지고 Series를 만들 수도 있습니다. dic의 key가 index로 사용되는 것을 확인 할 수 있습니다.
s2 = pd.Series({'서울' : 9_904_312, '부산' : 3_448_737, '인천' : 2_890_451, '대구' : 2_466_052})
s2Series index를 속성처럼 사용하기
만약 label 값이 영문 문자열인 경우에는 index label이 속성인 것처럼 마침표(.)를 활용하여 해당 index 값에 접근할 수 있습니다.
ser.a, ser.b, ser.cSeries의 특징
Series 객체는 index label을 키(key)로 사용하기에 딕셔너리 자료형과 비슷한 특징을 갖습니다.
그래서 Series를 딕셔너리와 같은 방식으로 사용할 수 있게 구현해놨습니다.
예를 들어 in 연산도 가능하고, items() 메서드를 사용해서 for문 루프를 돌려 각 요소의 키(key)와 값(value)에 접근 할 수 있습니다.
'서울' in s # 인덱스 레이블 중 서울이 있는가
'대전' in s # 인덱스 레이블 중 대전이 있는가
for k, v in s.itmes():
print(f'{k}, {v}')Series 연산하기
넘파이 배열처럼 Series도 벡터화 연산을 할 수 있습니다.
다만 연산은 Series의 value에만 적용되며 index 값은 변하지 않습니다.
s / 100000Series 인덱싱
Series는 넘파이 배열에서 가능한 index 방법 이외에도 index label을 이용한 인덱싱도 할 수 있습니다.
배열 인덱싱이나 index label을 이용한 슬라이싱(slicing)도 가능합니다.
s[1], s['부산']
s[3], s['대구']배열 인덱싱을 하면 부분적인 값을 가지는 Series 자료형을 반환합니다.
자료의 순서를 바꾸거나 특정한 자료만 취사 선택 할 수 있습니다.
s[[0,3,1]]
s[['서울', '대구', '부산']]Series 슬라이싱
슬라이싱을 해도 부분적인 Series를 반환합니다. 이 때 문자열 label을 이용한 슬라이싱을 하는 경우에는
숫자 인덱싱과 달리 콜론(:) 기호 뒤에 오는 값도 결과에 포함되므로 주의해야합니다.
s[1:3] # 두번째(1)부터 세번째(2)까지, 네번째(3) 미포함
s["부산":"대구"] # 부산에서 대구까지(대구도 포함)Sereis index 기반 연산
Seires 객체끼리 뺄셈이 가능합니다. numpy의 배열연산과 비슷합니다.
ds = s2 - s
dsSeries에서 값이 Nan인지 확인/ Nan이 아닌 값 구하기
Series 내 값이 Nan인지 아닌지 True/False로 반환 받으려면 notnull() 메서드를 사용하면 됩니다.
ds.notnull()
# notnull() 메서드로 구한 True / False 값을 활용하여 NaN인 값을 배제한 Series 객체를 만들 수 있습니다.
ds[ds.notnull()]Series 데이터 추가, 갱신, 삭제
딕셔너리와 비슷하게 인덱싱을 경우에 맞춰 사용하면 데이터를 추가(add)하거나 갱신(update)할 수 있습니다.
- 기존에 있는 index에 값을 할당하면 갱신됩니다.
rs = pd.Series([1.636984, 2.832690, 9.818107], index = ['부산','서울','인천'])
rs['부산'] = 1.63
rs없는 index에 값을 할당하면 Series에 데이터가 추가(add)됩니다.
아래 예제에는 '대구'라는 index는 현재 없는데 그 index에 값을 1.41할당하여 데이터를 추가하고 있습니다.
rs['대구'] = 1.41
rs데이터를 삭제할 때도 딕셔너리처럼 del 명령을 사용합니다.
아래 예제에서는 '서울'이라는 index에 접근하여 del 명령을 사용하여 데이터를 삭제하고 있습니다.
del rs['서울']
rs'데이터 분석 및 시각화 > 파이썬' 카테고리의 다른 글
| [Python] 클래스 연습문제 (1) | 2023.01.18 |
|---|---|
| [Python] 기초 정리(Pandas_DataFrame) (0) | 2023.01.18 |
| [Python] 기초 정리(Numpy) (0) | 2023.01.16 |
| [Python] 기초 정리(Class) (1) | 2023.01.13 |
| [Python] 기초 정리(전역변수, 지역변수, 람다(lambda)) (0) | 2023.01.13 |