
DataFrame Class
DataFrame은 Pandas의 주요 데이터 구조입니다. label된 row와 column, 두개의 축을 갖는 데이터 구조입니다.
산술 연산은 row와 column 모두 적용됩니다. Series 객체를 갖는 dictionary라고 생각하면 비슷합니다.
첫 인자로 data, 두 번째 인자로 index를 전달합니다.
- DataFrame은 각 column마다 자료형이 다를 수 있습니다.
DataFrame 생성
Series가 1차원 벡터 데이터에 행방향 index(row index)를 붙인것이라면 DataFrame 클래스는 2차원 행렬 데이터에 index를 붙인 것과 형태가 비슷합니다.
row와 column을 갖는 2차원이므로 각각의 행 데이터의 이름이 되는 행 index(row index) 뿐만 아니라
각각의 열 데이터의 이름이 되는 열 index(column index)도 붙일 수 있습니다.
DataFrame을 만드는 방법은 다양합니다. 가장 간단한 방법은 다음과 같습니다.
- 우선 하나의 열이 되는 데이터를 리스트나 일차원 배열을 준비합니다.
- 이 각각의 열에 대한 이름(label)을 키로 가지는 딕셔너리를 만듭니다.
- 이 데이터를 DataFrame 클래스 생성자에 넣는다. 동시에 열방향 index는 columns 인수로, 행방향 index는 index 인수로 지정합니다.
d = {'col1' : [1,2], 'col2' : [3, 4]}
df = pd.DataFrame(data = d)
dfdata = {
"2015": [9904312, 3448737, 2890451, 2466052],
"2010": [9631482, 3393191, 2632035, 2431774],
"2005": [9762546, 3512547, 2517680, 2456016],
"2000": [9853972, 3655437, 2466338, 2473990],
"지역": ["수도권", "경상권", "수도권", "경상권"],
"2010-2015 증가율": [0.0283, 0.0163, 0.0982, 0.0141]
}
columns = ["지역", "2015", "2010", "2005", "2000", "2010-2015 증가율"]
index = ["서울", "부산", "인천", "대구"]
df = pd.DataFrame(data, index=index, columns=columns)
dfDataFrame 이름 붙이기
- 컬럼명 : df.columns.name = '주가'
- 로우명 : df.index.name = '날짜'
# 데이터프레임 생성 예제
dict_ = {'코스피' : ['하락', '하락', '상승', '상승', '하락'],
'코스피 지수' : [2359.53, 2365.10, 2386.09, 2399.86, 2379.39],
'두산에너빌리티' : [16400, 16900, 17150, 16500, 16300],
'삼성전자' : [60500, 60500, 60800, 61100, 61000],
'셀바스AI' : [8250, 7980, 8510, 8600, 8820],
'레인보우로보틱스' : [53700, 49750, 54700, 56700, 63200],
}
df = pd.DataFrame(dict_, index = ['2023.01.11', '2023.01.12', '2023.01.13', '2023.01.16', '2023.01.17'])
# df.columns.name = '주가'
# df.index.name = '날짜'
dfDataFrame 전치(transpose)
df.TDataFrame column 추가, 갱신, 삭제
DataFrame은 column을 Series의 딕셔너리로 볼 수 있다고 했습니다. 즉 column 단위로 데이터를 갱신하거나 추가, 삭제할 수 있습니다.
아래 예제는 값을 갱신하고 있습니다.
df["2010-2015 증가율"] = df["2010-2015 증가율"] * 100아래 예제에서는 "2005-2010 증가율"이라는 이름의 column을 추가하고 있습니다.
기존에 없는 column인 "2005-2010 증가율"에 값을 할당해서 추가합니다.
df['2005-2010 증가율'] = (df['2010'] - df['2005']) / df['2005'] * 100).round(2)아래 예제에서는 "2010-2015 증가율"이라는 이름의 column을 삭제하고 있습니다.
del 명령을 통해 해당 column에 접근하여 삭제합니다.
del df['2010-2015 증가율']DataFrame column 인덱싱
DataFrame은 column label을 키로, column Series를 값으로 가지는 딕셔너리와 비슷하다고 하였습니다.
따라서 DataFrame을 인덱싱 할 때도 column label을 키(key)로 생각하여 인덱싱을 할 수 있습니다.
index로 label 값 하나만 넣으면 Series 객체가 반환됩니다.
df['지역']
df['2010']
type(df['2010']) # pandas.core.series.Serieslabel의 배열 또는 리스트로 인덱싱하면 DataFrame 객체가 반환됩니다.
df[['2010','2015']]만약 하나의 column만 빼내오더라도 DataFrame 자료형을 유지하고 싶다면 요소가 하나인 리스트 자료형을 사용해서 인덱싱하면 됩니다.
df[['2010']]
type(df[['2010']]) # pandas.core.frame.DataFrameDataFrame의 column index가 문자열 label일 때는 순서를 나타내는 정수 index를 column 인덱싱에 사용할 수 없습니다.
column index가 문자열인데 정수 index를 넣으면 KeyError가 발생하는 것을 볼 수 있습니다.
df[0]
# Key Error앞서 사용한 예제와 다르게 원래부터 문자열이 아닌 정수형 column index를 가지는 경우에는 index 값으로 정수를 사용할 수 있습니다.
df2 = pd.DataFrame(np.arange(12).reshape(3,4))
df2DataFrame row 슬라이싱
만약 row 단위로 인덱싱을 하고자하면 항상 슬라이싱(slicing)을 해야합니다. index의 값이 문자 label이면 label 슬라이싱도 가능합니다.
df
df[:1] # df[:'서울'] -> 문자는 포함, 숫자는 미포함DataFrame row 인덱싱할 경우
row 단위로 인덱싱 하면 KeyError가 발생되는 것을 확인할 수 있습니다.
DataFrame 개별 인덱싱
DataFrame에서 column label로 인덱싱하면 Series가 됩니다. 이 Series를 다시 row label로 인덱싱하면 개별 데이터가 나옵니다.
```
df['2015']['서울']
type(df['2015']['서울']) #numpy.int64
DataFrame 개별 데이터 인덱싱, 역순은 안될까?
DataFrame에서 row label로 인덱싱하면 KeyError가 발생됩니다. 그래도 굳이 row 단위로 먼저 시도하려면 슬라이싱 해야합니다.
그 때 반환 타입은 DataFrame이 됩니다. 이 DataFrame을 다시 column label로 인덱싱하면 개별 데이터가 아닌 Series 객체가 나옵니다.
즉 역순으로 하는 것은 썩 효율적이지 않음을 알 수 있습니다.
df['서울':'서울']
df['서울':'서울']['2015']
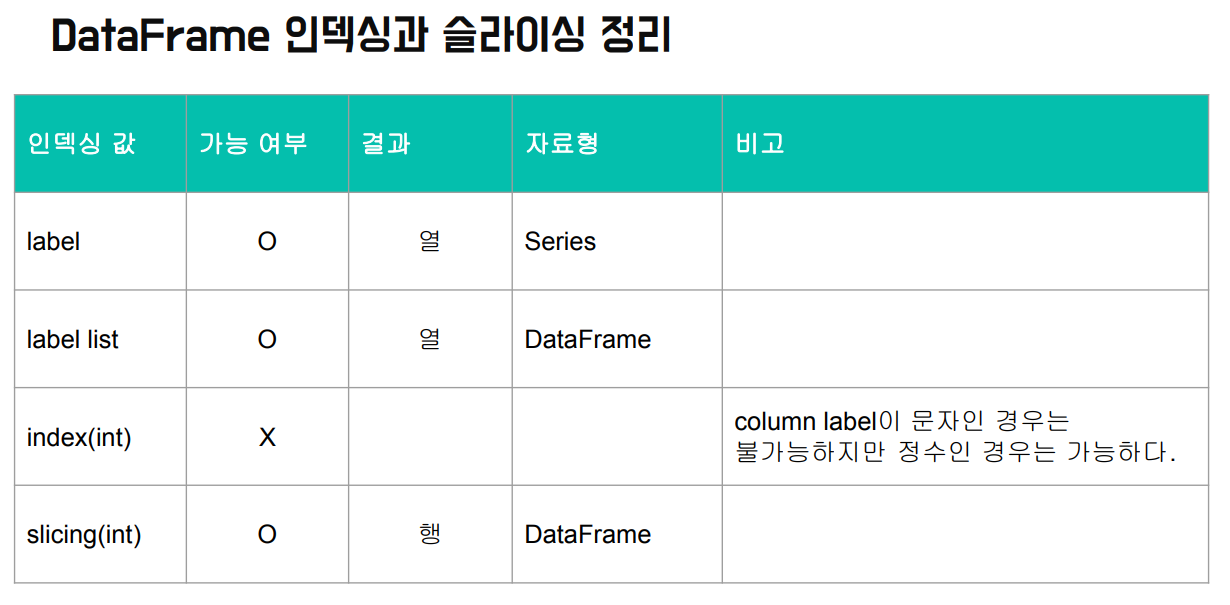
type(df['서울',:'서울']['2015'] # SeriesDataFrame 인덱싱과 슬라이싱 정리
연습문제
# 다음 데이터프레임을 만드세요
# 랜덤시드는 0입니다
# values는 넘파이 서브 패키지 중 random의 rand() 메서드를 사용하세요.
# pd.data_range("20130206", periods = 날짜수)를 활용하세요
np.random.seed(0)
pd.DataFrame(np.random.randn(6,4), index = pd.date_range("20130206", periods = 6), columns = ['A', 'B','C','D'])Pandas 데이터 입출력
Pandas는 데이터 파일을 읽어 DataFrame을 만들 수 있습니다.
csv는 콤마로 나누어진 파일입니다.
- pd.read_csv('데이터 경로', index = False, encoding = 'utf-8-sig')
# 컬럼명이랑 같이 저장하기
df = pd.read_csv('data/practice2.csv', names = ['c1','c2','c3'])Pandas 데이터 입력하기
df_read = pd.read_csv('data/practice1.csv')
# header(컬럼명) 없이 저장하기
df.to_csv('data/practice2.csv', index = False, header = False)
df_readPandas 데이터 읽기(sperator)
데이터를 구분자(separator)가 콤마(comma)가 아니면, sep 인수를 써서 구분자를 사용자가 지정해줘야합니다.
만약 길이가 정해지지 않은 공백이 구분자인 경우엔 '\s+' 정규식(regular expression) 문자열을 사용하면 됩니다.
%%writefile sample3.txt
c1 c2 c3 c4
0.179181 -1.538472 1.347553 0.43381
1.024209 0.087307 -1.281997 0.49265
0.417899 -2.002308 0.255245 -1.10515
df = pd.read_table('sample3.txt', sep = '\s+')Pandas 데이터 읽기(skiprows)
%%writefile sample4.txt
파일 제목: sample4.txt
데이터 포맷의 설명:
c1, c2, c3
1, 1.11, one
2, 2.22, two
3, 3.33, three
pd.read_csv('sample4.txt', skiprows = [0,1])Pandas 데이터 읽기(na_values)
데이터로 불러올 자료 안 특정한 값을 NaN으로 취급하고 싶으면 na_values 인수에 Nan 값으로 취급할 값을 넣습니다.
df_na_val = pd.read_csv('data/sample1.csv', na_values = ['누락'])
df_na_valPandas 데이터 csv 출력(sep)
파일을 읽을 때와 마찬가지로 파일을 출력할 때도 sep 인수로 구분자를 바꿀 수 있습니다.
df_na_val.to_csv('sample5.txt', sep = '|')
df_na_valPandas 데이터 csv 출력(na_rep)
또 불러올 때와 마찬가지로 저장할 때도 na_rep 키워드 인수를 사용해서 NaN 표시값을 바꿀 수도 있습니다.
아래의 코드를 보면 NaN 값을 '누락'으로 변경해서 저장합니다.
df_na_val.to_csv('sample5.txt', na_rep ='누락')온라인의 csv 파일 가져오기
웹상에는 다양한 데이터 파일이 CSV 파일 형태로 제공됩니다. read_csv 명령 사용시 path 대신 URL을 지정하면
Pandas가 직접 해당 파일을 다운로드하여 읽어들입니다.
다음은 웹사이트에 저장되어 있는 데이터를 읽어들이는 예제입니다.
pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')head, tail
만약 앞이나 뒤의 특정 개수만 보고싶다면 head() 메서드나 tail() 메서드를 사용하면 됩니다.
메서드 인수로 출력할 행의 수를 넣으면 됩니다.
'데이터 분석 및 시각화 > 파이썬' 카테고리의 다른 글
| [Python] 기초 정리(Pandas_DataFrame2) (2) | 2023.01.19 |
|---|---|
| [Python] 클래스 연습문제 (1) | 2023.01.18 |
| [Python] 기초 정리(Pandas_Series) (2) | 2023.01.18 |
| [Python] 기초 정리(Numpy) (0) | 2023.01.16 |
| [Python] 기초 정리(Class) (1) | 2023.01.13 |