
목차
실습 1. 헤더가 없는 CSV 파일 처리하기
- 입력 데이터 : 헤더가 없는 CSV 파일
- 데이터에 스키마 지정하기
- SparkConf 사용해보기
- measure_type 값이 TMIN인 레코드 대상으로 stationId별 최소 온도 찾기
1) Spark로 CSV 로드(SparkSession, conf, Schema 지정)
from pyspark.sql import SparkSession
from pyspark import SparkConf
# SparkConf로 SparkSession의 환경 설정
conf = SparkConf()
# application의 이름
conf.set("spark.app.name", "PySpark DataFrame #1")
# master 설정, local 모든 스레드를 가져오겠다
conf.set("spark.master", "local[*]")
# spark이란 이름으로 spark session 오브젝트 설정
spark = SparkSession.builder\
.config(conf=conf)\
.getOrCreate()- Conf로 세션 설정 후, Session을 Build 합니다(Singleton Pattern)
# 데이터프레임으로 로드
# long form : spark.read.format("csv").load("./data/1800.csv")
# short form : spark.read.csv("1800.csv")
# s3 path여도 가능하다.
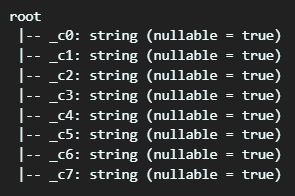
df = spark.read.format("csv").load("./data/1800.csv") # spark.read.csv("1800.csv")- csv 포맷의 파일을 load합니다.
- 이때 경로에는 로컬에 있는 csv 파일 뿐만 아니라, s3 path 및 연동 된 다양한 path가 가능합니다.
- 이 때 스키마 입력이 없었으므로, schema는 기본 값인 string으로, null 값은 true로 지정됩니다.
# spark 데이터프레임 로드하지만, toDF로 로드 해서, 컬럼 이름 지정
# 간단하게 컬럼의 이름을 지정해주는 것
df = spark.read.format("csv")\
.load("./data/1800.csv")\
.toDF("stationID", "date", "measure_type", "temperature", "_c4", "_c5", "_c6", "_c7")
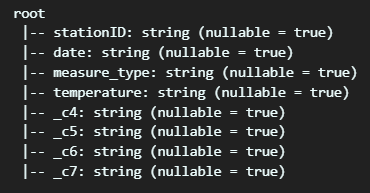
df.printSchema()- 불러온 파일을 데이터프레임 형태로 전환합니다. 이 때, 컬럼 개수에 맞게 파라미터로 이름을 넘겨주면, 컬럼명이 생깁니다.
- 다만 Schema를 입력하지 않았기 때문에, 여전히 Schema는 모두 디폴트 값으로 입력되어 있습니다.
# inferSchema를 true로 지정하면, spark에서 앞의 샘플을 추출해서 schema를 추측해서 지정
df = spark.read.format("csv")\
.option("inferSchema", "true")\
.load("./data/1800.csv")\
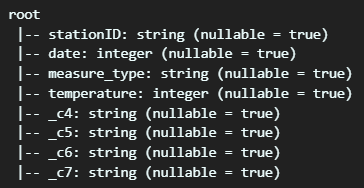
.toDF("stationID", "date", "measure_type", "temperature", "_c4", "_c5", "_c6", "_c7")- inferSchema를 쓰면 spark에서 앞의 일부를 두고, Schema를 추정하여 반환합니다.
from pyspark.sql.types import StringType, IntegerType, FloatType
from pyspark.sql.types import StructType, StructField
# 제대로 schema를 정의하고 로드하기
# StructFiled , 컬럼명, 타입, True면 null 값이 가능하다
schema = StructType([ \
StructField("stationID", StringType(), True), \
StructField("date", IntegerType(), True), \
StructField("measure_type", StringType(), True), \
StructField("temperature", FloatType(), True)])- StructType 안에 StructFiled로 컬럼명, 타입, null 값 허용 방식을 작성하면, schema를 지정할 수 있습니다.
# df = spark.read.schema(schema).format("csv").load("1800.csv")
# 이렇게한 후에 로드하면, 앞에 4가지 컬럼에 대해서 지정한대로 들어간다.
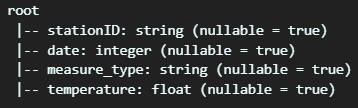
df = spark.read.schema(schema).csv("./data/1800.csv")- 이후 스키마를 이용해서, csv를 read하면 지정된 컬럼 개수 대로 앞에서 schema가 갖춰진 채, load 됩니다.
2) Spark로 데이터 조작하기(DataFrame 연관 메소드)
# Filter out all but TMIN entries
minTemps = df.filter(df.measure_type == "TMIN")
# Column expression으로 필터링 적용
minTemps = df.where(df.measure_type == "TMIN")
# SQL expression으로 필터링 적용
minTemps = df.where("measure_type = 'TMIN'")
minTemps.count()- Filter 방식에는 크게 두가지로, filter 메소드와 where 메소드를 사용할 수 있습니다.
- 이 중 where 메소드는 SQL expression, Column expression으로 필터링을 적용할 수 있습니다.
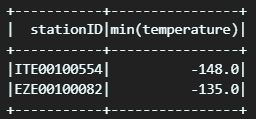
# Aggregate to find minimum temperature for every station
minTempsByStation = minTemps.groupBy("stationID").min("temperature")
minTempsByStation.show()- 앞서 filter가 된 minTemps 변수의 데이터를 groupBy 한 후, temperature 컬럼 값을 중심으로 min 값을 뽑습니다.
- 이후 해당 변수를 show() 출력합니다.
- show의 인수로 특정 숫자를 넣으면 앞에서 특정 개수만큼 출력합니다.
# Select only stationID and temperature
stationTemps = minTemps[["stationID", "temperature"]]
# 원하는 컬럼 나열 가능
stationTemps = minTemps.select("stationID", "temperature")- 특정 컬럼을 지정하는 방법엔 두 가지가 있습니다.
- Pandas의 방식으로 지정, select 메소드를 활용하여 지정
# Collect, format, and print the results
# collect 하면 파이썬 쪽으로 받아온다.(리스트 형태로 받아옴)
results = minTempsByStation.collect()
for result in results:
print(result[0] + "\t{:.2f}F".format(result[1]))- collect 메소드를 사용하면, Spark에 있던 변수를 python으로 리스트 형태로 가져옵니다.
3) Spark SQL로 데이터 처리하기
# INPUT이 되는 데이터프레임 생성
df.createOrReplaceTempView("station1800")
# spark sql로 results 만든 후, collect
results = spark.sql("""SELECT stationID, MIN(temperature)
FROM station1800
WHERE measure_type = 'TMIN'
GROUP BY 1""").collect()- 데이터프레임으로 임시 뷰를 생성한 후,
- 해당 뷰를 sql로 가공 후, collect(파이썬 쪽으로 가져옵니다.
# pyspark.sql.Row는 DataFrame의 레코드에 해당하며 필드별로 이름이 존재
for r in results:
print(r)
SparkSQL을 활용하면, 정형 데이터에 대한 가공을 훨씬 짧고 가독성 있게, 진행할 수 있습니다.
4) Pyspark.sql.types

5) Spark에서 DataFrame의 컬럼을 지칭하는 방식
from pyspark.sql.functions import col, column
stationTemps = minTemps.select(
"stationID",
col("stationID"),
column("stationID"),
minTemps.stationID
)- 데이터프레임의 컬럼을 다음 세가지 방법으로 지정할 수 있습니다.
- 컬럼명 문자열로 작성
- col, column
'데이터 엔지니어링 > Spark' 카테고리의 다른 글
| 10. Spark DataFrame 실습(텍스트 파싱 -> 구조화 데이터 변환, 윈도우 Hadoop.dll 관련 에러해결법) (0) | 2023.08.17 |
|---|---|
| 9. Spark DataFrame 실습(Alias, catalog) (0) | 2023.08.17 |
| 7. 윈도우에 Local Standalone Spark 클러스터 설치, Spark-submit 오류 해결, findspark (0) | 2023.07.28 |
| 6. Spark(개발환경 옵션, Local Standalone, 활용 Demo) (0) | 2023.07.28 |
| 5. Spark 프로그램 구조(Spark Session 생성, 환경변수) (1) | 2023.07.11 |
실습 1. 헤더가 없는 CSV 파일 처리하기
- 입력 데이터 : 헤더가 없는 CSV 파일
- 데이터에 스키마 지정하기
- SparkConf 사용해보기
- measure_type 값이 TMIN인 레코드 대상으로 stationId별 최소 온도 찾기
1) Spark로 CSV 로드(SparkSession, conf, Schema 지정)
from pyspark.sql import SparkSession
from pyspark import SparkConf
# SparkConf로 SparkSession의 환경 설정
conf = SparkConf()
# application의 이름
conf.set("spark.app.name", "PySpark DataFrame #1")
# master 설정, local 모든 스레드를 가져오겠다
conf.set("spark.master", "local[*]")
# spark이란 이름으로 spark session 오브젝트 설정
spark = SparkSession.builder\
.config(conf=conf)\
.getOrCreate()- Conf로 세션 설정 후, Session을 Build 합니다(Singleton Pattern)
# 데이터프레임으로 로드
# long form : spark.read.format("csv").load("./data/1800.csv")
# short form : spark.read.csv("1800.csv")
# s3 path여도 가능하다.
df = spark.read.format("csv").load("./data/1800.csv") # spark.read.csv("1800.csv")- csv 포맷의 파일을 load합니다.
- 이때 경로에는 로컬에 있는 csv 파일 뿐만 아니라, s3 path 및 연동 된 다양한 path가 가능합니다.
- 이 때 스키마 입력이 없었으므로, schema는 기본 값인 string으로, null 값은 true로 지정됩니다.
# spark 데이터프레임 로드하지만, toDF로 로드 해서, 컬럼 이름 지정
# 간단하게 컬럼의 이름을 지정해주는 것
df = spark.read.format("csv")\
.load("./data/1800.csv")\
.toDF("stationID", "date", "measure_type", "temperature", "_c4", "_c5", "_c6", "_c7")
df.printSchema()- 불러온 파일을 데이터프레임 형태로 전환합니다. 이 때, 컬럼 개수에 맞게 파라미터로 이름을 넘겨주면, 컬럼명이 생깁니다.
- 다만 Schema를 입력하지 않았기 때문에, 여전히 Schema는 모두 디폴트 값으로 입력되어 있습니다.
# inferSchema를 true로 지정하면, spark에서 앞의 샘플을 추출해서 schema를 추측해서 지정
df = spark.read.format("csv")\
.option("inferSchema", "true")\
.load("./data/1800.csv")\
.toDF("stationID", "date", "measure_type", "temperature", "_c4", "_c5", "_c6", "_c7")- inferSchema를 쓰면 spark에서 앞의 일부를 두고, Schema를 추정하여 반환합니다.
from pyspark.sql.types import StringType, IntegerType, FloatType
from pyspark.sql.types import StructType, StructField
# 제대로 schema를 정의하고 로드하기
# StructFiled , 컬럼명, 타입, True면 null 값이 가능하다
schema = StructType([ \
StructField("stationID", StringType(), True), \
StructField("date", IntegerType(), True), \
StructField("measure_type", StringType(), True), \
StructField("temperature", FloatType(), True)])- StructType 안에 StructFiled로 컬럼명, 타입, null 값 허용 방식을 작성하면, schema를 지정할 수 있습니다.
# df = spark.read.schema(schema).format("csv").load("1800.csv")
# 이렇게한 후에 로드하면, 앞에 4가지 컬럼에 대해서 지정한대로 들어간다.
df = spark.read.schema(schema).csv("./data/1800.csv")- 이후 스키마를 이용해서, csv를 read하면 지정된 컬럼 개수 대로 앞에서 schema가 갖춰진 채, load 됩니다.
2) Spark로 데이터 조작하기(DataFrame 연관 메소드)
# Filter out all but TMIN entries
minTemps = df.filter(df.measure_type == "TMIN")
# Column expression으로 필터링 적용
minTemps = df.where(df.measure_type == "TMIN")
# SQL expression으로 필터링 적용
minTemps = df.where("measure_type = 'TMIN'")
minTemps.count()- Filter 방식에는 크게 두가지로, filter 메소드와 where 메소드를 사용할 수 있습니다.
- 이 중 where 메소드는 SQL expression, Column expression으로 필터링을 적용할 수 있습니다.
# Aggregate to find minimum temperature for every station
minTempsByStation = minTemps.groupBy("stationID").min("temperature")
minTempsByStation.show()- 앞서 filter가 된 minTemps 변수의 데이터를 groupBy 한 후, temperature 컬럼 값을 중심으로 min 값을 뽑습니다.
- 이후 해당 변수를 show() 출력합니다.
- show의 인수로 특정 숫자를 넣으면 앞에서 특정 개수만큼 출력합니다.
# Select only stationID and temperature
stationTemps = minTemps[["stationID", "temperature"]]
# 원하는 컬럼 나열 가능
stationTemps = minTemps.select("stationID", "temperature")- 특정 컬럼을 지정하는 방법엔 두 가지가 있습니다.
- Pandas의 방식으로 지정, select 메소드를 활용하여 지정
# Collect, format, and print the results
# collect 하면 파이썬 쪽으로 받아온다.(리스트 형태로 받아옴)
results = minTempsByStation.collect()
for result in results:
print(result[0] + "\t{:.2f}F".format(result[1]))- collect 메소드를 사용하면, Spark에 있던 변수를 python으로 리스트 형태로 가져옵니다.
3) Spark SQL로 데이터 처리하기
# INPUT이 되는 데이터프레임 생성
df.createOrReplaceTempView("station1800")
# spark sql로 results 만든 후, collect
results = spark.sql("""SELECT stationID, MIN(temperature)
FROM station1800
WHERE measure_type = 'TMIN'
GROUP BY 1""").collect()- 데이터프레임으로 임시 뷰를 생성한 후,
- 해당 뷰를 sql로 가공 후, collect(파이썬 쪽으로 가져옵니다.
# pyspark.sql.Row는 DataFrame의 레코드에 해당하며 필드별로 이름이 존재
for r in results:
print(r)
SparkSQL을 활용하면, 정형 데이터에 대한 가공을 훨씬 짧고 가독성 있게, 진행할 수 있습니다.
4) Pyspark.sql.types
5) Spark에서 DataFrame의 컬럼을 지칭하는 방식
from pyspark.sql.functions import col, column
stationTemps = minTemps.select(
"stationID",
col("stationID"),
column("stationID"),
minTemps.stationID
)- 데이터프레임의 컬럼을 다음 세가지 방법으로 지정할 수 있습니다.
- 컬럼명 문자열로 작성
- col, column
'데이터 엔지니어링 > Spark' 카테고리의 다른 글
| 10. Spark DataFrame 실습(텍스트 파싱 -> 구조화 데이터 변환, 윈도우 Hadoop.dll 관련 에러해결법) (0) | 2023.08.17 |
|---|---|
| 9. Spark DataFrame 실습(Alias, catalog) (0) | 2023.08.17 |
| 7. 윈도우에 Local Standalone Spark 클러스터 설치, Spark-submit 오류 해결, findspark (0) | 2023.07.28 |
| 6. Spark(개발환경 옵션, Local Standalone, 활용 Demo) (0) | 2023.07.28 |
| 5. Spark 프로그램 구조(Spark Session 생성, 환경변수) (1) | 2023.07.11 |