
Gradient Boosting(GBM)
- 에이다부스트와 유사: 앙상블에 이전까지의 오차를 보정하면서 예측기를 순차적으로 추가
- 다른 점: 반복 시 샘플의 가중치를 추가하는 대신 이전 예측기가 만든 잔여 오차에 새로운 예측기를 학습 시킴. 가중치 업데이트를 경사 하강법으로 이용
- 오류값: 실제값 – 예측값 (잔여오차)

- 이 오류식이 최소화되도록 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 방식
- 일반적으로 GBM이 랜덤 포레스트보다 예측 성능이 뛰어난 경우가 많지만, 수행 시간이 오래 걸리고 하이퍼파라미터 튜닝 노력도 더 필요함
XGBOOST
LighGBM
- 장점
- XGBOOST보다 학습에 걸리는 시간이 짧음
- 예측 성능은 비슷, 더 작은 메모리 사용량
- 보다 다양한 기능 제공
- 단점
- 데이터 세트가 적은 경우(10000 이하) 과적합이 발생하기 쉬움
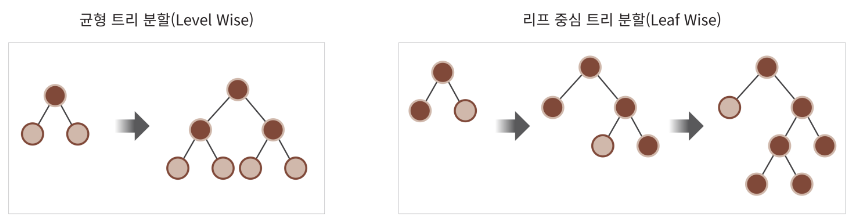
- 작동 방식(일반 GBM 방법 VS LightGBM)
- 균형트리분할(Level Wise) 방식, 트리 깊이 최소화, 과적합 방지, 균형을 맞추기위한 시간 필요
- LightGBM
리프 중심 트리 분할(Leaf Wise) 방식 : 트리의 균형을 맞추지 않고, 최대 손실값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고, 비대칭적인 규칙 트리를 생성, 최대 손실값을 가지는 리프노드를 지속적으로 분할하여 생성된 규칙트리는 학습을 반복할수록 결국 균형트리분할방식보다 예측 오류 손실을 최소화할 수 있음
LGBM, XGBOOST 과적합 개선 팁
과적합을 방지하는 방법은 학습 모델을 단순화하는 방향으로 하이퍼 파라미터 튜닝
- learning_rate은 낮추고 n_estimators는 높임
- max_depth 낮춤
- min_child_weight: 높임
- min_split_loss : 높임
- sub_samples : 낮춤
- colsample_bytree: 낮춤
CatBoosting
'머신러닝 및 딥러닝 > 머신러닝' 카테고리의 다른 글
| 오버샘플링 vs 언더샘플링 (0) | 2023.02.14 |
|---|---|
| 스태킹 앙상블(Stacking Ensemble, 블렌딩) (0) | 2023.02.14 |
| 앙상블 이론 (0) | 2023.02.13 |
| 결정트리 이론 (0) | 2023.02.10 |
| 로지스틱 회귀 이론(분류), 분류 성능평가지표 (0) | 2023.02.09 |