
텍스트 분석
텍스트 분석이란?
다양한 형태의 텍스트 (문자열 타입의 데이터)를 컴퓨터를 이용하여 수집하고, 이를 통계 혹은 기계학습 등의 방법을 사용해서 분석하는 것. 텍스트 분석을 통해서 텍스트의 특성을 파악하고 텍스트가 담고 있는 정보와 특정 주제에 대한 여러가지 인사이트를 얻을 수 있음.
텍스트 데이터의 종류
텍스트 데이터에는 신문기사, 블로그, 사회연결망사이트의 글 (예, Tweets), 댓글, 상품 정보, 연설문, 이메일 등 굉장히 다양한 종류가 존재함.
NLP vs Text Analysis
- 자연어처리
- 머신이 인간의 언어를 이해하고 해석하는데 중점. 기계번역, 자동 질의 응답 시스템
- 텍스트 분석
- 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 비즈니스 인텔리전스나 예측 분석등의 작업을 주로 수행
- 텍스트 분류(Text Classification)
- 감성 분석(Sentiment Analysis)
- 텍스트 요약(Summaraization)
- 텍스트 군집화(Clustering)와 유사도 측정
텍스트 분석 수행 프로세스
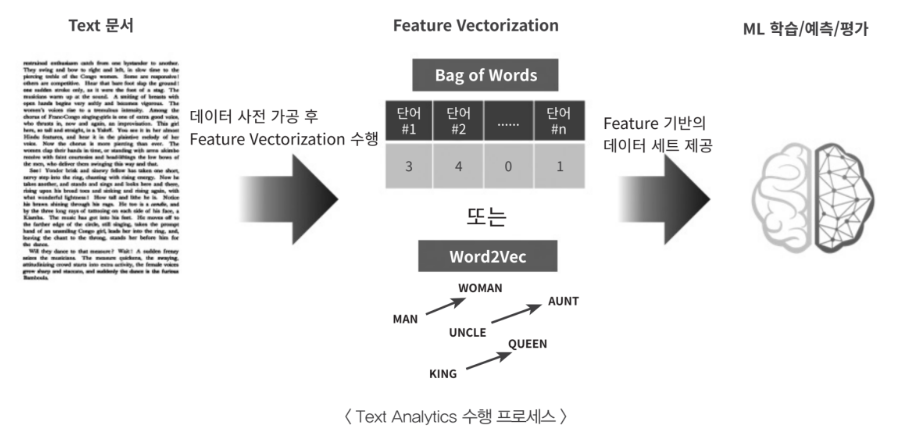
- 텍스트 전처리
- 피처 벡터화/추출
- ML 모델 수립 및 학습/예측/평가
파이썬 텍스트 분석 library 설치
- NLPK(Natural Language Toolkit for Python)
- 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 패키지
- 다양한 기능 및 예제를 가지고 있음
- 주요기능
- 말뭉치(Corpus) : 자연어 분석 작업을 위해 만들어 놓은 샘플 문서 집합(소설, 신문...)
- 토큰 생성 – 긴 문자열을 분석을 위한 작은 단위로 만들어 놓은 것
- 형태소 분석 – 언어학에서 일정한 의미가 있는 말의 단위
- 어간 추출(stemming)
- 원형 복원(lemmatizing)
- 품사 부착(part of speech tagging)
- Konlpy : 한국어 정보처리를 위한 파이썬 패키지
[참조]용어정리
- 텍스트 원자료는 일정한 단위로 구성되어 있음 - 게시물, 댓글, 기사, 멘션 ...
- 원자료는 더욱 세부적인 레벨로 쪼개어 분석할 수 있음 - 문단, 문장, 단어 ...
- 분석목적에 따라 텍스트의 데이터의 단위를 조절해가며 사용해야함
- 범용적으로 사용되는 텍스트 데이터 단위의 명칭
- Corpus (말뭉치) : 특정한 목적에 따라 추출한 텍스트 표본의 집합
- 한국어 신문기사 말뭉치, 네이버 영화리뷰 텍스트, 전기차관련 social media 게시물 집합
- Document (문서): corpus 내의 개별 텍스트데이터의 단위
-
- 기사1개, 영화리뷰 1개, instagram 게시물1개
- Paragraph (문단)
- Sentence (문장)
- word (단어)
- Token : 토큰은 분석을 위해 분리되고 정제된 텍스트의 단위를 지칭함. 위의 분류가 고정적인 것에 비해 토큰의 단위는 분석에 따라 상이함.
- 예시문장: “빙빙 돌아가는 회전목마 처럼 영원히 계속될것 처럼”
- Lemmatization(표제어추출) → 품사선택 → unigram 토크나이징 : 빙빙, 돌다, 회전목마, 영원히, 계속되다
- Lemmatization(표제어추출) → 품사선택 → bigram 토크나이징 : 빙빙_돌다, 돌다_회전목마, 회전목마_영원히, 영원히_계속되다
- Corpus (말뭉치) : 특정한 목적에 따라 추출한 텍스트 표본의 집합
텍스트 전처리(텍스트 정규화)
텍스트 자체를 바로 피처로 만들 수 없으며, 사전에 텍스트를 가공하는 단계클렌징, 정제, 토큰화, 필터링/불용어(stop word) 제거/철자 수정, 어근화(Stemming/Lemmatization) 등을 수행
텍스트 정제(Cleansing)
- 텍스트 분석에 오히려 방해가 되는 불필요한 문자, 기호 사전 제거.(HTML, XML태그, 특정 기호 등)
텍스트 토큰화(Tokenization)
- 마침표(.), 개행문자(‘\n’) 등의 기호에 따라 분리, 각 문장이 가지는 시맨틱 의미가 중요할 때
- 정규 표현식을 사용해 다양한 유형으로 토큰화 수행
- 단어의 순서가 중요하지 않은 경우, 문장 토큰화 대신 단어 토큰화만 해도 충분함
- 문제점
- 문장을 단어별로 하나씩 토큰화할 경우 문맥적 의미가 무시됨
- n-gram 대안(연속된 n개의 단어를 하나씩 토큰화 단위로 분리) 제시텍스트 불용어 제거(Stop word removal)
- 분석에 큰 의미가 없는 단어(is, the, a, will...)
- 문법적인 특성으로 인해 특히 빈번하게 텍스트로 나타나므로 사전에 제거하지 않으면 빈번함으로 인해 오히려 중요한 단어로 인지될 수 있음.
- NLTK는 다양한 언어의 스톱 워드 제공
텍스트 어근화(stemming and Lemmatization)
- 문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것(과거형, 현재형, 3인칭 단수, 진행형 등)
- stemming보다 Lemmatization이 보다 정교하게 원형을 찾음.(품사와 같은 문법적 요소까지 고려)
품사태깅(Part of Speech tagging)
- 품사 태그 정보를 활용하면 원하는 품사(명사 등)만 선택 가능
- untag() 메소드를 활용하여 품사 정보 제거 가능
감성분석
텍스트 임베딩(피처 벡터화) - Bags of Words(BOW)
텍스트나 단어는 머신러닝 알고리즘에 주입하기 전에 수치 형태로 변환해야함, 텍스트를 수치나 특성 벡터로 표현하는 것

- 쉽고 빠른 구현 – 단순히 단어 발생 빈도 기반이지만 예상보다 문서의 특징을 잘 나타내며, 전통적으로 여러 분야에서 활용도가 높음.
- 단, 문맥 의미(Semantic Context) 를 잘 반역하지 못함(n-gram으로 대안 제시)
- 희소 행렬이 발생함. BOW로 피처 벡터화를 수행하면, 많은 문서에서 단어를 추출할 경우 하나의 문서에 있는 단어는 이 중 극히 일부분이므로 대부분의 데이터가 0으로 채워짐. 알고리즘의 수행 시간과 예측 성능을 떨어뜨림.
사이킷런의 CountVectorizer
- 사이킷런의 CountVectorizer 클래스를 사용하여 각각의 문서에 있는 단어 카운트를 기반으로 한 BOW 모델을 구현할 수 있음.
- CountVectorizer의 fit_transform()을 호출하면 BOW모델의 어휘사전을 구축하고 아래 세문자를 희소특성 벡터로 변환함
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
doc = np.array([
'The sun is shining',
'The weather is sweet',
'The sun is shining, the weather is sweet, and one and one is two'])
bag = count.fit_transform(docs)
bag- 단어 빈도(term frequency)
- 문서 d에 등장한 단어 t의 횟수
- Bow 모델은 문장이나 문서에서 등장하는 단어의 순서를 상관하지 않음
'머신러닝 및 딥러닝 > 딥러닝' 카테고리의 다른 글
| NLP - 전이학습 (0) | 2023.03.02 |
|---|---|
| 순환신경망(RNN) PART2 (0) | 2023.02.28 |
| 순환신경망(RNN) (0) | 2023.02.27 |
| 객체탐지와 합성곱 신경망 (0) | 2023.02.27 |
| 합성곱 신경망 데이터 증강(ImageDataGenerator 사용하기) (0) | 2023.02.23 |
텍스트 분석
텍스트 분석이란?
다양한 형태의 텍스트 (문자열 타입의 데이터)를 컴퓨터를 이용하여 수집하고, 이를 통계 혹은 기계학습 등의 방법을 사용해서 분석하는 것. 텍스트 분석을 통해서 텍스트의 특성을 파악하고 텍스트가 담고 있는 정보와 특정 주제에 대한 여러가지 인사이트를 얻을 수 있음.
텍스트 데이터의 종류
텍스트 데이터에는 신문기사, 블로그, 사회연결망사이트의 글 (예, Tweets), 댓글, 상품 정보, 연설문, 이메일 등 굉장히 다양한 종류가 존재함.
NLP vs Text Analysis
- 자연어처리
- 머신이 인간의 언어를 이해하고 해석하는데 중점. 기계번역, 자동 질의 응답 시스템
- 텍스트 분석
- 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 비즈니스 인텔리전스나 예측 분석등의 작업을 주로 수행
- 텍스트 분류(Text Classification)
- 감성 분석(Sentiment Analysis)
- 텍스트 요약(Summaraization)
- 텍스트 군집화(Clustering)와 유사도 측정
텍스트 분석 수행 프로세스
- 텍스트 전처리
- 피처 벡터화/추출
- ML 모델 수립 및 학습/예측/평가
파이썬 텍스트 분석 library 설치
- NLPK(Natural Language Toolkit for Python)
- 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 패키지
- 다양한 기능 및 예제를 가지고 있음
- 주요기능
- 말뭉치(Corpus) : 자연어 분석 작업을 위해 만들어 놓은 샘플 문서 집합(소설, 신문...)
- 토큰 생성 – 긴 문자열을 분석을 위한 작은 단위로 만들어 놓은 것
- 형태소 분석 – 언어학에서 일정한 의미가 있는 말의 단위
- 어간 추출(stemming)
- 원형 복원(lemmatizing)
- 품사 부착(part of speech tagging)
- Konlpy : 한국어 정보처리를 위한 파이썬 패키지
[참조]용어정리
- 텍스트 원자료는 일정한 단위로 구성되어 있음 - 게시물, 댓글, 기사, 멘션 ...
- 원자료는 더욱 세부적인 레벨로 쪼개어 분석할 수 있음 - 문단, 문장, 단어 ...
- 분석목적에 따라 텍스트의 데이터의 단위를 조절해가며 사용해야함
- 범용적으로 사용되는 텍스트 데이터 단위의 명칭
- Corpus (말뭉치) : 특정한 목적에 따라 추출한 텍스트 표본의 집합
- 한국어 신문기사 말뭉치, 네이버 영화리뷰 텍스트, 전기차관련 social media 게시물 집합
- Document (문서): corpus 내의 개별 텍스트데이터의 단위
-
- 기사1개, 영화리뷰 1개, instagram 게시물1개
- Paragraph (문단)
- Sentence (문장)
- word (단어)
- Token : 토큰은 분석을 위해 분리되고 정제된 텍스트의 단위를 지칭함. 위의 분류가 고정적인 것에 비해 토큰의 단위는 분석에 따라 상이함.
- 예시문장: “빙빙 돌아가는 회전목마 처럼 영원히 계속될것 처럼”
- Lemmatization(표제어추출) → 품사선택 → unigram 토크나이징 : 빙빙, 돌다, 회전목마, 영원히, 계속되다
- Lemmatization(표제어추출) → 품사선택 → bigram 토크나이징 : 빙빙_돌다, 돌다_회전목마, 회전목마_영원히, 영원히_계속되다
- Corpus (말뭉치) : 특정한 목적에 따라 추출한 텍스트 표본의 집합
텍스트 전처리(텍스트 정규화)
텍스트 자체를 바로 피처로 만들 수 없으며, 사전에 텍스트를 가공하는 단계클렌징, 정제, 토큰화, 필터링/불용어(stop word) 제거/철자 수정, 어근화(Stemming/Lemmatization) 등을 수행
텍스트 정제(Cleansing)
- 텍스트 분석에 오히려 방해가 되는 불필요한 문자, 기호 사전 제거.(HTML, XML태그, 특정 기호 등)
텍스트 토큰화(Tokenization)
- 마침표(.), 개행문자(‘\n’) 등의 기호에 따라 분리, 각 문장이 가지는 시맨틱 의미가 중요할 때
- 정규 표현식을 사용해 다양한 유형으로 토큰화 수행
- 단어의 순서가 중요하지 않은 경우, 문장 토큰화 대신 단어 토큰화만 해도 충분함
- 문제점
- 문장을 단어별로 하나씩 토큰화할 경우 문맥적 의미가 무시됨
- n-gram 대안(연속된 n개의 단어를 하나씩 토큰화 단위로 분리) 제시텍스트 불용어 제거(Stop word removal)
- 분석에 큰 의미가 없는 단어(is, the, a, will...)
- 문법적인 특성으로 인해 특히 빈번하게 텍스트로 나타나므로 사전에 제거하지 않으면 빈번함으로 인해 오히려 중요한 단어로 인지될 수 있음.
- NLTK는 다양한 언어의 스톱 워드 제공
텍스트 어근화(stemming and Lemmatization)
- 문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것(과거형, 현재형, 3인칭 단수, 진행형 등)
- stemming보다 Lemmatization이 보다 정교하게 원형을 찾음.(품사와 같은 문법적 요소까지 고려)
품사태깅(Part of Speech tagging)
- 품사 태그 정보를 활용하면 원하는 품사(명사 등)만 선택 가능
- untag() 메소드를 활용하여 품사 정보 제거 가능
감성분석
텍스트 임베딩(피처 벡터화) - Bags of Words(BOW)
텍스트나 단어는 머신러닝 알고리즘에 주입하기 전에 수치 형태로 변환해야함, 텍스트를 수치나 특성 벡터로 표현하는 것
- 쉽고 빠른 구현 – 단순히 단어 발생 빈도 기반이지만 예상보다 문서의 특징을 잘 나타내며, 전통적으로 여러 분야에서 활용도가 높음.
- 단, 문맥 의미(Semantic Context) 를 잘 반역하지 못함(n-gram으로 대안 제시)
- 희소 행렬이 발생함. BOW로 피처 벡터화를 수행하면, 많은 문서에서 단어를 추출할 경우 하나의 문서에 있는 단어는 이 중 극히 일부분이므로 대부분의 데이터가 0으로 채워짐. 알고리즘의 수행 시간과 예측 성능을 떨어뜨림.
사이킷런의 CountVectorizer
- 사이킷런의 CountVectorizer 클래스를 사용하여 각각의 문서에 있는 단어 카운트를 기반으로 한 BOW 모델을 구현할 수 있음.
- CountVectorizer의 fit_transform()을 호출하면 BOW모델의 어휘사전을 구축하고 아래 세문자를 희소특성 벡터로 변환함
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
doc = np.array([
'The sun is shining',
'The weather is sweet',
'The sun is shining, the weather is sweet, and one and one is two'])
bag = count.fit_transform(docs)
bag- 단어 빈도(term frequency)
- 문서 d에 등장한 단어 t의 횟수
- Bow 모델은 문장이나 문서에서 등장하는 단어의 순서를 상관하지 않음
'머신러닝 및 딥러닝 > 딥러닝' 카테고리의 다른 글
| NLP - 전이학습 (0) | 2023.03.02 |
|---|---|
| 순환신경망(RNN) PART2 (0) | 2023.02.28 |
| 순환신경망(RNN) (0) | 2023.02.27 |
| 객체탐지와 합성곱 신경망 (0) | 2023.02.27 |
| 합성곱 신경망 데이터 증강(ImageDataGenerator 사용하기) (0) | 2023.02.23 |