
transformer 모델의 등장
- Attention Is All You Need
- 2017년 자연어 처리 논문에서 처음 제안(By google)
- 논문에서 제안된 트랜스포머의 구조는 현재 사용되는 거의 모든 자연어 처리 관련 모델의 선조
- 등장 이후 자연어 처리 분야를 평정했을 만큼 트랜스포머는 강력했으며 언어적 특징을 가장 잘 고려한 모델
- 현재 자연어 전이 학습 사전 훈련 모델은 거의 모두 트랜스 포머의 변형임
- 모든 기존 정보를 다 뒤집는 경우 SOTA(State Of The Art)
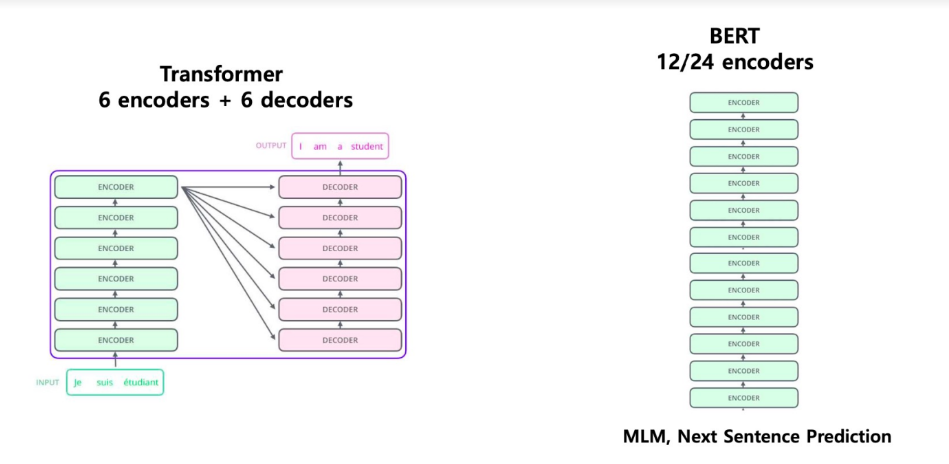
- 트랜스포머의 ENCODER로 만든게 BERT
- 트랜스포머의 DECODER로 만든게 GPT

전이학습 개요
- 데이터가 충분하지 않은 상황에서 방대한 자료를 통해 미리 학습한 가중값을 가져와서, 다양한 분야에 사용
전이학습

자연어처리 학습 모델
- ELMO (Embeddings from Language Model)
- Bidirectional LSTM 을 이용하여 양방향으로 문맥 전체를 파악
- (단, 각각의 방향에 대해 autoregressive 한 language model)
- OpenAI GPT(Generative Pre-Training Transformer)
- Transformer 의 decoder 12 개를 쌓아서 구성
- decoder 를 사용하므로 이전 단어들 만으로 다음 단어 예측
- (forward language model, autoregressive)
- BERT(Bidirectional Encoder Representational from Transformers)
- Transformer 의 encoder 12/24 개를 쌓아서 구성
- MLM(Masked Language Model), Next Sentence Prediction 으로 학습
- GLUE Benchmark(General Language Understanding Evaluation)
- 모델의 자연어 이해 능력을 평가
- Task Dataset 9개로 구성
- CoLA (The Corpus of Linguistic Acceptability)
- 문장이 문법적으로 오류가 없는가(2진 분류)
- SST-2 (The Stanford Sentiment Treebank)
- 영화평 감상 분류 ( positive, negative, neutral)
- MRPD (Microsoft Research Paraphrase Corpus)
- 문장 B가 문장 A의 다른 표현(paraphrase)인가(2진 분류)
- STS-B (The Semantic Textual Similarity Benchmark)
- 문장 A와 문장 B는 얼마나 유사한가(유사도 측정)
- QQO (Quora Question Paris)
- 두 개의 질문이 유사한가(이진 분류) SST-2 (The Stanford Sentiment Treebank)
- 영화평 감상 분류 ( positive, negative, neutral)
- MNLI (Multi-Gense Natural Language Inference)
- 문장 B가 문장 A에 이어지는 문장인지, 반대되는 문장인지, 무관한 문장인지 여부
- 문장 A (Hypothesis) vs. 문장 B (Premise)
- QNLI (Question Natural Language Inference)
- 문장 B가 문장 A의 질문에 대한 답을 포함하는가 (이진 분류)
- RTE (Recognizing Textual Entailment)
- MNLI와 유사하나 상대적으로 훨씬 적은 데이터셋으로 평가(이진 분류)
- WNLI (Winograd NLI)
- 문장 B가 문장 A의 애매한 대명사를 정확한 명사로 대체하는가(이진 분류)
- CoLA (The Corpus of Linguistic Acceptability)
- BERT 사전 훈련 언어모델
- 2018년에 구글이 개발한 NLP(자연어처리) 사전 훈련 기술
- 훈련 데이터: Wikipedia(25억 단어) &BookCorpus(8억 단어) ≈ 33억 단어
- 세서미 스트리트라는 미국 인형극의 케릭터 BERT 이름을 따온 것
- ALBERT, RoBERTA, TinyBERT 등 다양한 변종이 있음
- BERT의 특징
- 이전의 대부분 모델은 왼쪽에서 오른쪽으로 진행하여 문맥(context)를 파악, 전체 문장을 이해하는데 한계점을 가짐, BERT는 양방향성을 포함하여 문맥을 더욱 자연스럽게 파악함



'머신러닝 및 딥러닝 > 딥러닝' 카테고리의 다른 글
| 자연어처리(텍스트 전처리, 감성분석) (0) | 2023.02.28 |
|---|---|
| 순환신경망(RNN) PART2 (0) | 2023.02.28 |
| 순환신경망(RNN) (0) | 2023.02.27 |
| 객체탐지와 합성곱 신경망 (0) | 2023.02.27 |
| 합성곱 신경망 데이터 증강(ImageDataGenerator 사용하기) (0) | 2023.02.23 |